在 Flink 中,状态可靠性保证由 Checkpoint 支持,当作业出现 failover 的情况下,Flink 会从最近成功的 Checkpoint 恢复。在实际情况中,我们可能会遇到 Checkpoint 失败,或者 Checkpoint 慢的情况,本文会统一聊一聊 Flink 中 Checkpoint 异常的情况(包括失败和慢),以及可能的原因和排查思路。
1. Checkpoint 流程简介
首先我们需要了解 Flink 中 Checkpoint 的整个流程是怎样的,在了解整个流程之后,我们才能在出问题的时候,更好的进行定位分析。
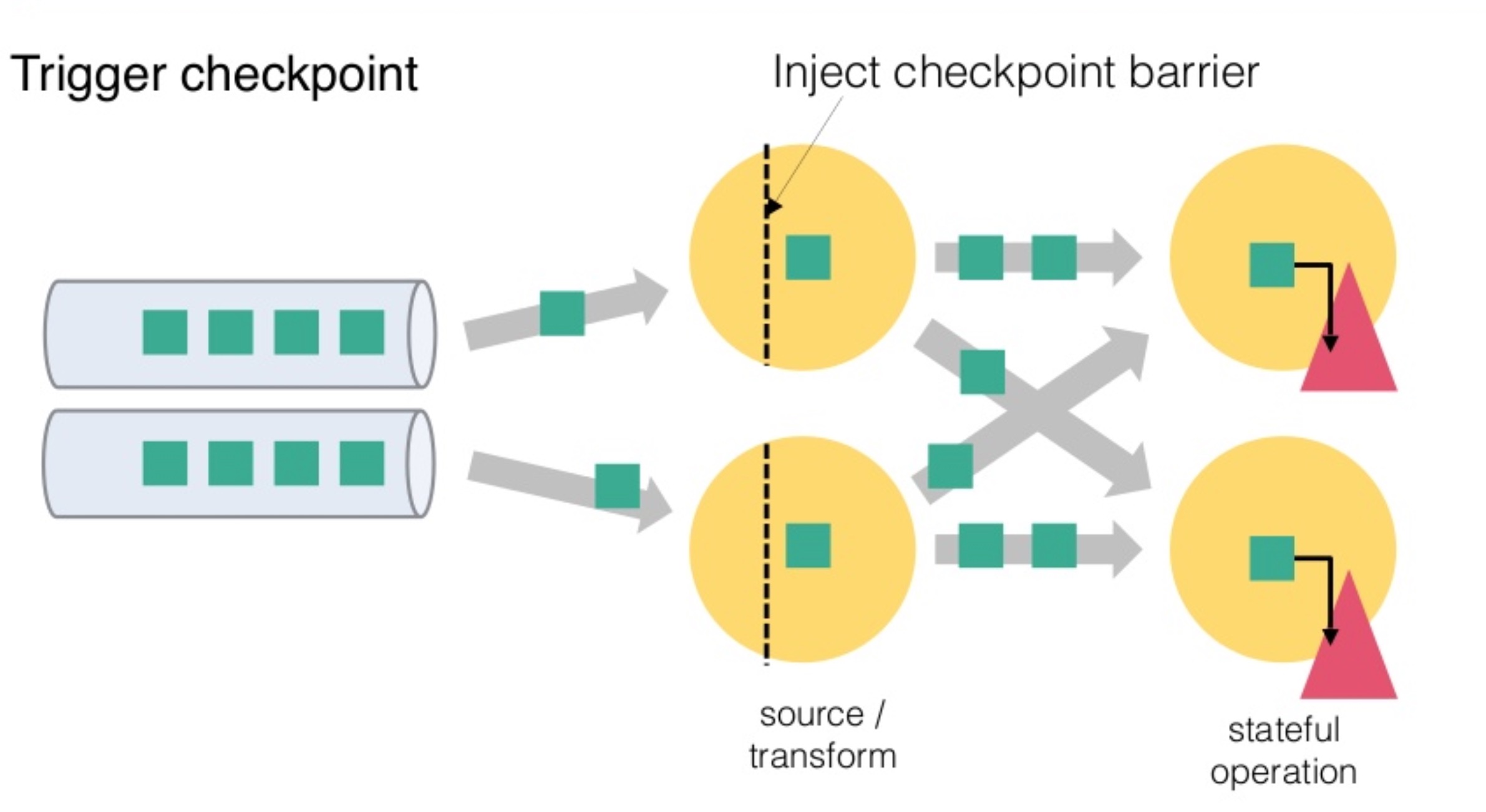
从上图我们可以知道,Flink 的 Checkpoint 包括如下几个部分:
- JM trigger checkpoint
- Source 收到 trigger checkpoint 的 PRC,自己开始做 snapshot,并往下游发送 barrier
- 下游接收 barrier(需要 barrier 都到齐才会开始做 checkpoint)
- Task 开始同步阶段 snapshot
- Task 开始异步阶段 snapshot
- Task snapshot 完成,汇报给 JM
上面的任何一个步骤不成功,整个 checkpoint 都会失败。
2 Checkpoint 异常情况排查
2.1 Checkpoint 失败
可以在 Checkpoint 界面看到如下图所示,下图中 Checkpoint 10423 失败了。
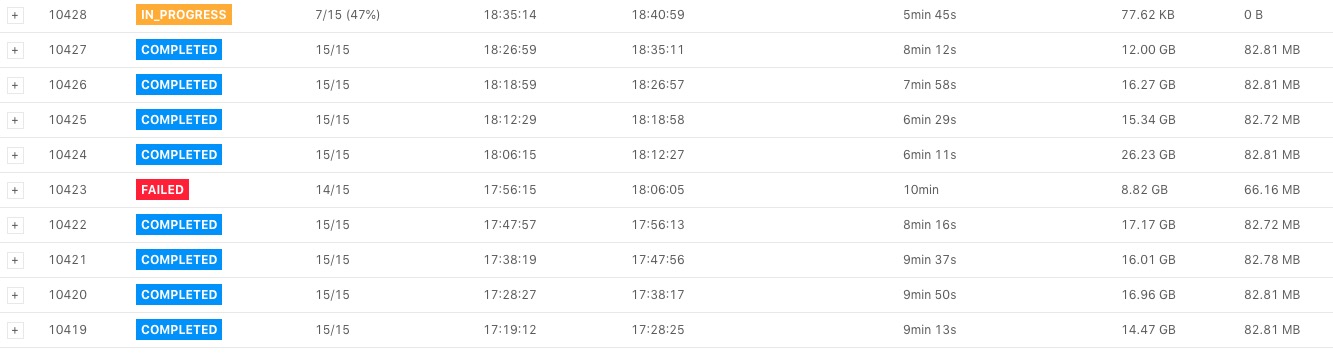
点击 Checkpoint 10423 的详情,我们可以看到类系下图所示的表格(下图中将 operator 名字截取掉了)。
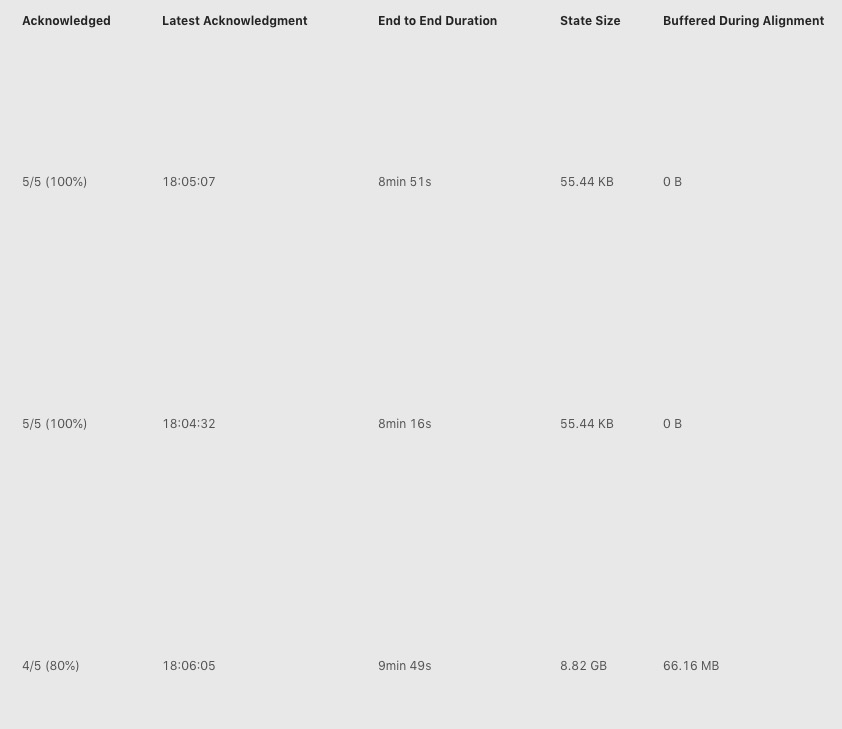
上图中我们看到三行,表示三个 operator,其中每一列的含义分别如下:
- 其中
Acknowledged一列表示有多少个 subtask 对这个 Checkpoint 进行了 ack,从图中我们可以知道第三个 operator 总共有 5 个 subtask,但是只有 4 个进行了 ack; - 第二列
Latest Acknowledgement表示该 operator 的所有 subtask 最后 ack 的时间; End to End Duration表示整个 operator 的所有 subtask 中完成 snapshot 的最长时间;State Size表示当前 Checkpoint 的 state 大小 – 主要这里如果是增量 checkpoint 的话,则表示增量大小;Buffered During Alignment表示在 barrier 对齐阶段积攒了多少数据,如果这个数据过大也间接表示对齐比较慢);
Checkpoint 失败大致分为两种情况:Checkpoint Decline 和 Checkpoint Expire。
2.2 Checkpoint 慢
2.2.1 使用增量 Checkpoint
现在 Flink 中 Checkpoint 有两种模式,全量 Checkpoint 和 增量 Checkpoint,其中全量 Checkpoint 会把当前的 state 全部备份一次到持久化存储,而增量 Checkpoint,则只备份上一次 Checkpoint 中不存在的 state,因此增量 Checkpoint 每次上传的内容会相对更好,在速度上会有更大的优势。
现在 Flink 中仅在 RocksDBStateBackend 中支持增量 Checkpoint,如果你已经使用 RocksDBStateBackend,可以通过开启增量 Checkpoint 来加速,具体的可以参考 [2]。
2.2.2 作业存在反压或者数据倾斜
我们知道 task 仅在接受到所有的 barrier 之后才会进行 snapshot,如果作业存在反压,或者有数据倾斜,则会导致全部的 channel 或者某些 channel 的 barrier 发送慢,从而整体影响 Checkpoint 的时间,这两个可以通过如下的页面进行检查:
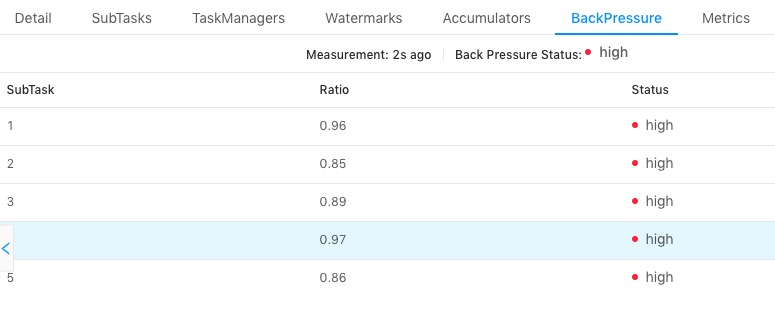
上图中我们选择了一个 task,查看所有 subtask 的反压情况,发现都是 high,表示反压情况严重,这种情况下会导致下游接收 barrier 比较晚。
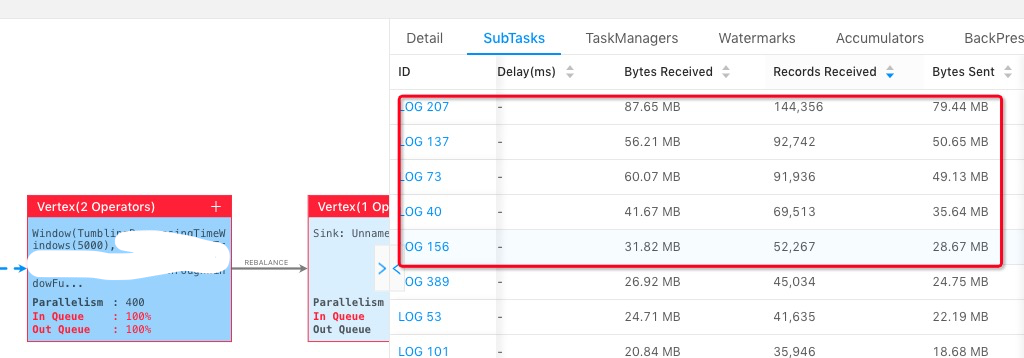
上图中我们选择其中一个 operator,点击所有的 subtask,然后按照 Records Received/Bytes Received/TPS 从大到小进行排序,能看到前面几个 subtask 会比其他的 subtask 要处理的数据多。
如果存在反压或者数据倾斜的情况,我们需要首先解决反压或者数据倾斜问题之后,再查看 Checkpoint 的时间是否符合预期。
2.2.2 Barrier 对齐慢
从前面我们知道 Checkpoint 在 task 端分为 barrier 对齐(收齐所有上游发送过来的 barrier),然后开始同步阶段,再做异步阶段。如果 barrier 一直对不齐的话,就不会开始做 snapshot。
barrier 对齐之后会有如下日志打印:
1 | DEBUG |
 )如果
)如果 taskmanager.log 中没有这个日志,则表示 barrier 一直没有对齐,接下来我们需要了解哪些上游的 barrier 没有发送下来,如果你使用 At Least Once 的话,可以观察下面的日志:
1 | DEBUG |
)表示该 task 收到了 channel 5 来的 barrier,然后看对应 Checkpoint,再查看还剩哪些上游的 barrier 没有接受到,对于 ExactlyOnce 暂时没有类似的日志,可以考虑自己添加,或者 jmap 查看。
从实现上看,Flink 通过在 DAG 数据源定时向数据流注入名为 Barrier 的特殊元素,将连续的数据流切分为多个有限序列,对应多个 Checkpoint 周期。每当接收到 Barrier,算子进行本地的 Checkpoint 快照,并在完成后异步上传本地快照,同时将 Barrier 以广播方式发送至下游。当某个 Checkpoint 的所有 Barrier 到达 DAG 末端且所有算子完成快照,则标志着全局快照的成功。
图2. Barrier Alignment
在有多个输入 Channel 的情况下,为了数据准确性,算子会等待所有流的 Barrier 都到达之后才会开始本地的快照,这种机制被称为 Barrier 对齐。在对齐的过程中,算子只会继续处理的来自未出现 Barrier Channel 的数据,而其余 Channel 的数据会被写入输入队列,直至在队列满后被阻塞。当所有 Barrier 到达后,算子进行本地快照,输出 Barrier 到下游并恢复正常处理。
比起其他分布式快照,该算法的优势在于辅以 Copy-On-Write 技术的情况下不需要 “Stop The World” 影响应用吞吐量,同时基本不用持久化处理中的数据,只用保存进程的状态信息,大大减小了快照的大小。
2.2.4 同步阶段做的慢
同步阶段一般不会太慢,但是如果我们通过日志发现同步阶段比较慢的话,对于非 RocksDBBackend 我们可以考虑查看是否开启了异步 snapshot,如果开启了异步 snapshot 还是慢,需要看整个 JVM 在干嘛,也可以使用前一节中的工具。对于 RocksDBBackend 来说,我们可以用 iostate 查看磁盘的压力如何,另外可以查看 tm 端 RocksDB 的 log 的日志如何,查看其中 SNAPSHOT 的时间总共开销多少。
RocksDB 开始 snapshot 的日志如下:
1 | 2019/09/10-14:22:55.734684 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:83] Started the snapshot process -- creating snapshot in directory /tmp/flink-io-87c360ce-0b98-48f4-9629-2cf0528d5d53/XXXXXXXXXXX/chk-92729 |
)
snapshot 结束的日志如下:
1 | 2019/09/10-14:22:56.001275 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:145] Snapshot DONE. All is good |
。
对于 RocksDB 来说,则需要从本地读取文件,写入到远程的持久化存储上,所以不仅需要考虑网络的瓶颈,还需要考虑本地磁盘的性能。另外对于 RocksDBBackend 来说,如果觉得网络流量不是瓶颈,但是上传比较慢的话,还可以尝试考虑开启多线程上传功能[3]。
3 总结
在第二部分内容中,我们介绍了官方编译的包的情况下排查一些 Checkpoint 异常情况的主要场景,以及相应的排查方法,如果排查了上面所有的情况,还是没有发现瓶颈所在,则可以考虑添加更详细的日志,逐步将范围缩小,然后最终定位原因。
上文提到的一些 DEBUG 日志,如果 flink dist 包是自己编译的话,则建议将 Checkpoint 整个步骤内的一些 DEBUG 改为 INFO,能够通过日志了解整个 Checkpoint 的整体阶段,什么时候完成了什么阶段,也在 Checkpoint 异常的时候,快速知道每个阶段都消耗了多少时间。
参考内容
[1] Change threading-model in StreamTask to a mailbox-based approach
[2] 增量 checkpoint 原理介绍
[3] RocksDBStateBackend 多线程上传 State