[TOC]

1.简单介绍一下Flink吧
简单来说,Flink 是一个分布式的流处理框架,它能够对有界和无界的数据流进行高效的处理。Flink 的核心是流处理,当然它也能支持批处理,Flink 将批处理看成是流处理的一种特殊情况,即数据流是有明确界限的。这和 Spark Streaming 的思想是完全相反的,Spark Streaming 的核心是批处理,它将流处理看成是批处理的一种特殊情况, 即把数据流进行极小粒度的拆分,拆分为多个微批处理。
2.数据倾斜的问题?
我们的checkpoint失败,我们有失败告警机制,会发短信告知你。checkpoint机制是用于失败恢复依赖于 检查点机制 + 可部分重发的数据源。检查点机制机制:checkpoint定期触发,产生快照,快照中记录了:
1 | 当前检查点开始时数据源(例如Kafka)中消息的offset。 |
当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
快照的核心概念之一是barrier。 这些barrier被注入数据流并与记录一起作为数据流的一部分向下流动。barrier将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。每个barrier都带有快照的ID,并且barrier之前的记录都进入了该快照。
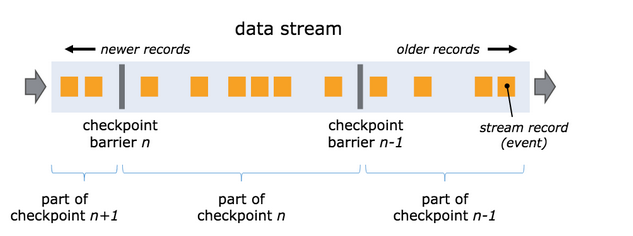
快照n的barriers被插入的位置(记之为Sn)是快照所包含的数据在数据源中最大位置。
1.思考使用增量 Checkpoint
现在 Flink 中 Checkpoint 有两种模式,全量 Checkpoint 和 增量 Checkpoint,其中全量 Checkpoint 会把当前的 state 全部备份一次到持久化存储,而增量 Checkpoint,则只备份上一次 Checkpoint 中不存在的 state,因此增量 Checkpoint 每次上传的内容会相对更好,在速度上会有更大的优势。
2.Barrier 对齐慢
从前面我们知道 Checkpoint 在 task 端分为 barrier 对齐(收齐所有上游发送过来的 barrier),然后开始同步阶段,再做异步阶段。如果 barrier 一直对不齐的话,就不会开始做 snapshot。
3.同步异步状态出问题
1.同步阶段:task执行状态快照,并写入外部存储系统(根据状态后端的选择不同有所区别)
执行快照的过程:
a.对state做深拷贝。
b.将写操作封装在异步的FutureTask中
FutureTask的作用包括:1)打开输入流2)写入状态的元数据信息3)写入状态4)关闭输入流
2.异步阶段:
1)执行同步阶段创建的FutureTask
2)向Checkpoint Coordinator发送ACK响应
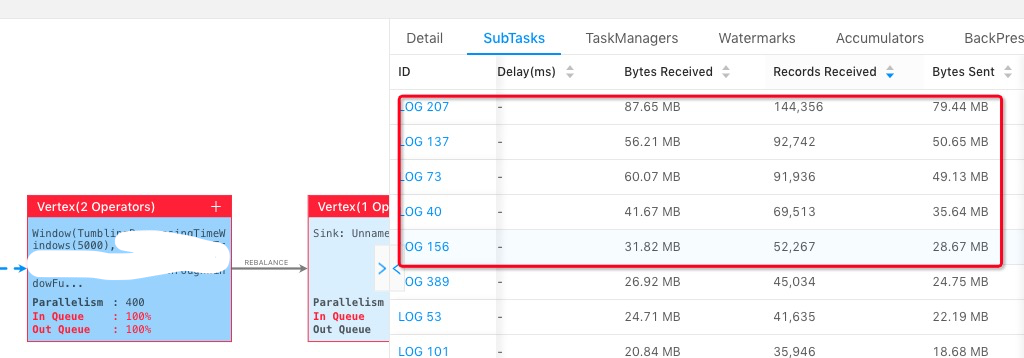
4.数据倾斜的问题
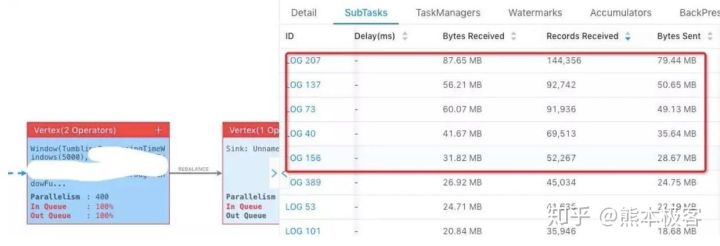
source并发度与分区数相一致
加上随机的前后缀
keyBy + 斜杠 输出端加入split
3.反压。
4.反压的解决:Netty 水位值机制
Task 1 在输出端有一个相关联的 LocalBufferPool(称缓冲池1),Task 2 在输入端也有一个相关联的 LocalBufferPool(称缓冲池2)。如果缓冲池1中有空闲可用的 buffer 来序列化记录 “A”,我们就序列化并发送该 buffer。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。我们上面描述的这个方案可以从两个 Task 之间的数据传输自然地扩展到更复杂的 pipeline 中,保证反压机制可以扩散到整个 pipeline。
下方的代码是初始化 NettyServer 时配置的水位值参数。
1 | // 默认高水位值为2个buffer大小, 当接收端消费速度跟不上,发送端会立即感知到 |
当输出缓冲中的字节数超过了高水位值, 则 Channel.isWritable() 会返回false。当输出缓存中的字节数又掉到了低水位值以下, 则 Channel.isWritable() 会重新返回true。Flink 中发送数据的核心代码在 PartitionRequestQueue 中,该类是 server channel pipeline 的最后一层。
3.改进checkpoint
https://blog.csdn.net/qq_35939417/article/details/105586436
现象:每次重启Flink Task,都会往elasticsearch发送已经计算过的数据。比如本来elasticsearch有3条记录,在不往Kafka生产新消息的情况下,重新启动Flink Task之后有6条,再重启是9条,说明数据重复。

上面意思是说,当启用Flink的Checkpointing机制后,默认的offset提交策略是:Flink Kafka消费者会在每次设置检查点完成后提交Kafka的offset。此时配置Kafka消费者的enable.auto.commit是无效的,亲测一直都是false。可以通过setCommitOffsetsOnCheckpoints(false)取消提交Offset与设置检查点之间的关联。
然后我看代码,之前的某位大神把设置检查点的时间间隔设置成了三小时,意思就是说消费者是每三小时提交一次offset,这就不奇怪为什么重启会有大量数据重复了。之前我就怀疑这个参数配置有问题,果然是个坑。最后改成5秒设置一次检查点,数据重复的问题就解决了。
4.怎么用UDAF
1亿 20多位 20B 2GB
假如这 1亿个整数的数据范围是 0 到 100 亿,那么就需要申请 100 亿个 bit 约等于 1200MB
布隆过滤器 true false
redis进行存储是放得下的
自定义UDAF
city_id, use_id
1 | /** |
5.Redis的问题
检查日志 有重启过,关闭checkpoint
- jmap分析: 通过jmap查看堆使用排行,惊讶的发现排在第一是Atomiclong类,占堆内存达到恐怖的2.7G,而我们的代码并没有显示使用Atomiclong类,排第二的是[C,表示字符串,字符串在程序中用的很多,排第二属正常,第三还是Atomiclong类,这个Atomiclong类究竟是哪个对象引用的呢?第四是genericonobjectpool,这个也不正常,程序中连接池对象竟然有372198个,哪里用得了这么多,还有一个jedisFactory类,一个工厂类竟然也有37万个实例,也是有问题的。
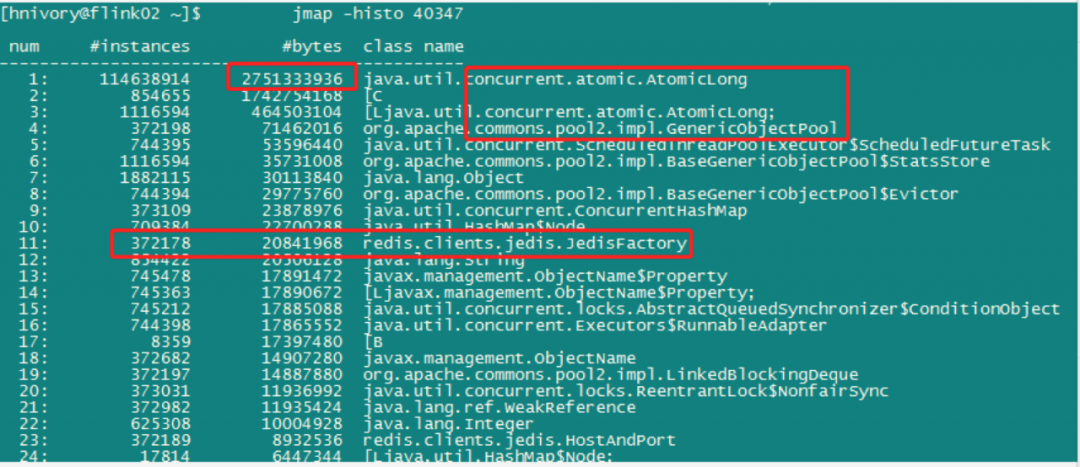
mat分析:
通过简单的jmap命令,发现很多不正常的类占据着堆内存的前几名,这些类究竟有什么关系,谁才是罪魁祸首?只好使出我们的终极MAT分析大法。
通过分析导出生成的dump, 整个dump文件有6.7G,使用32G内存的机器经过10多分钟的处理,才得到以下分析结果。
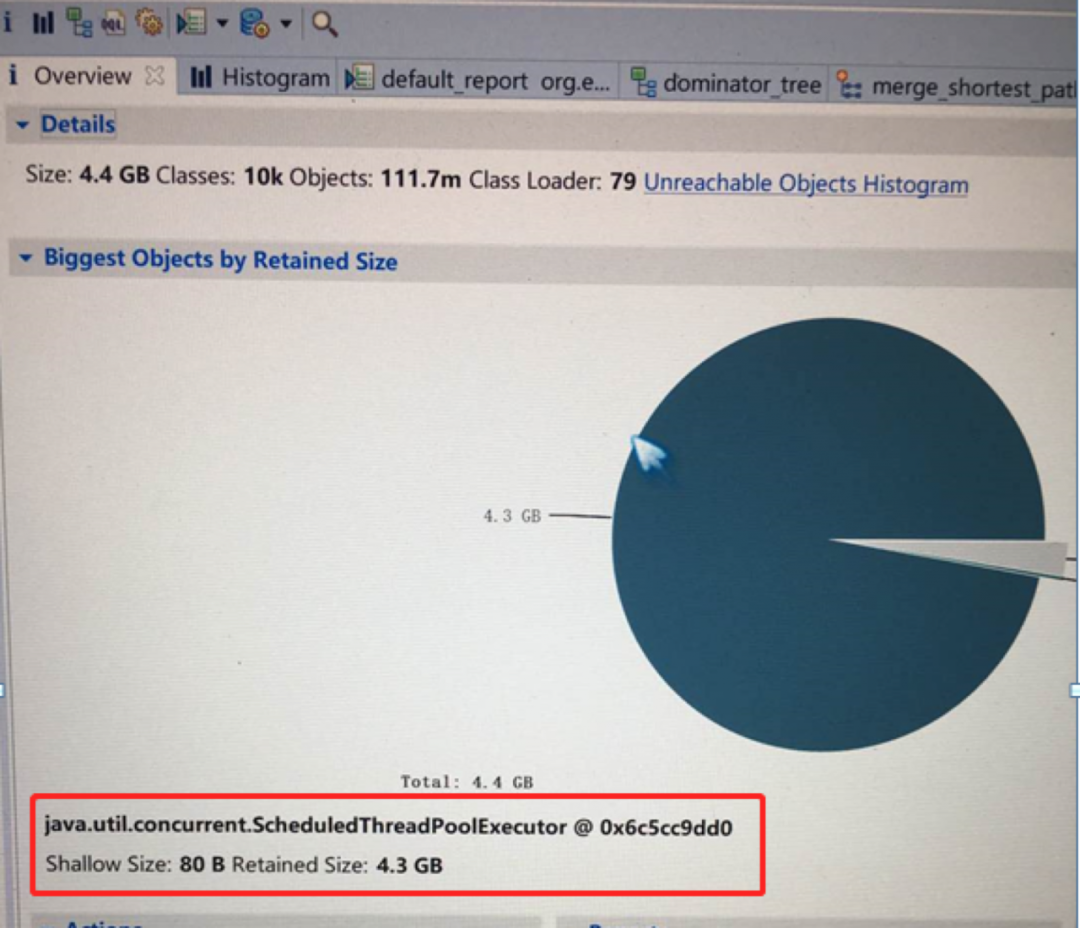
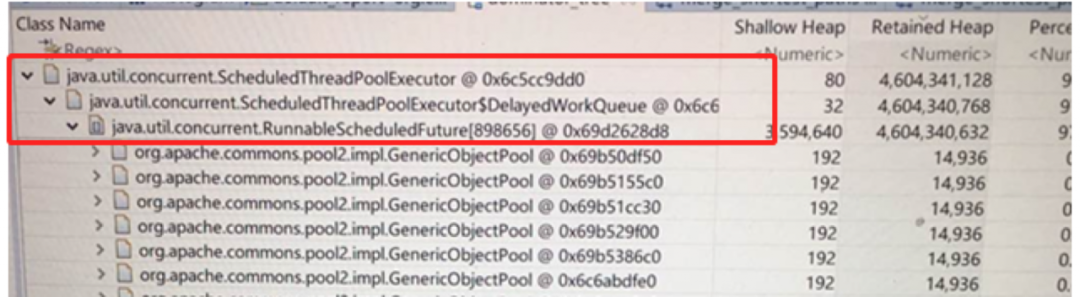
分析报告显示ScheduledThreadPoolExecutor对象持有4.3GB堆内存未释放,堆饼图中占有97%
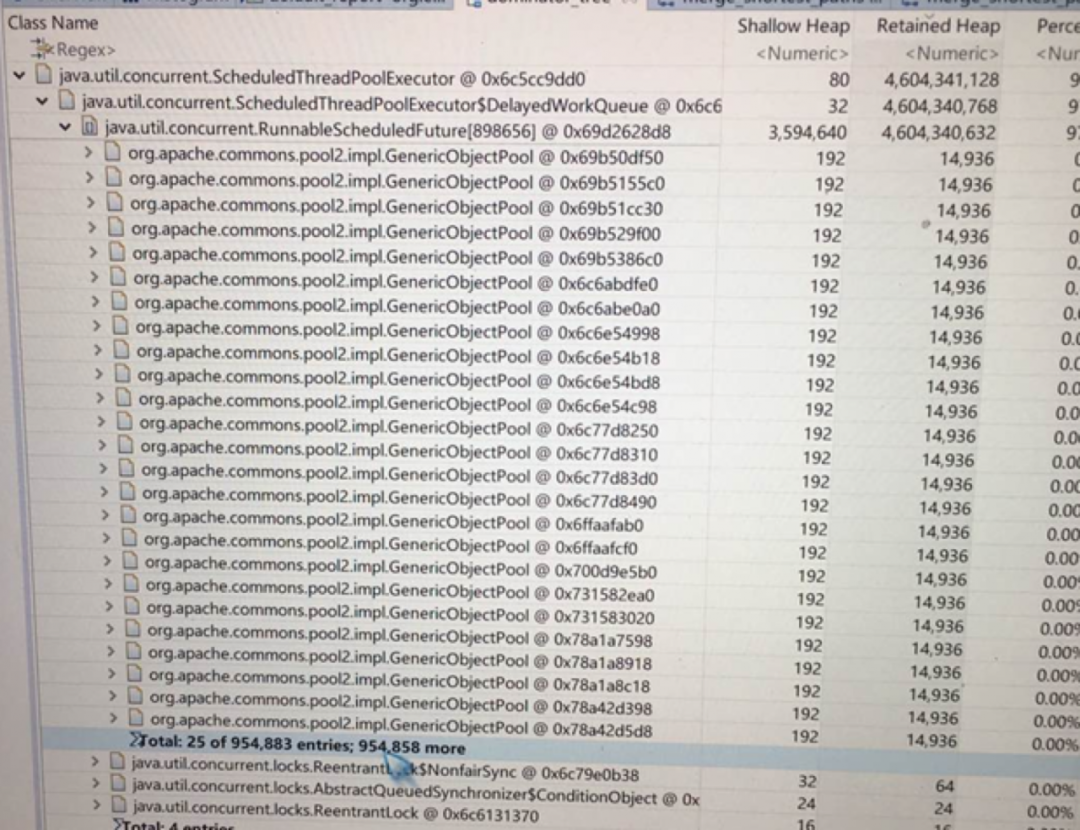
点进去查看树图,发现ScheduledThreadPoolExecutor对象持有4.3GB堆内存全部是GenericObjectPool对象(4.3G,接近1百万个对象)
再点击GenericObjectPool展开后发现:
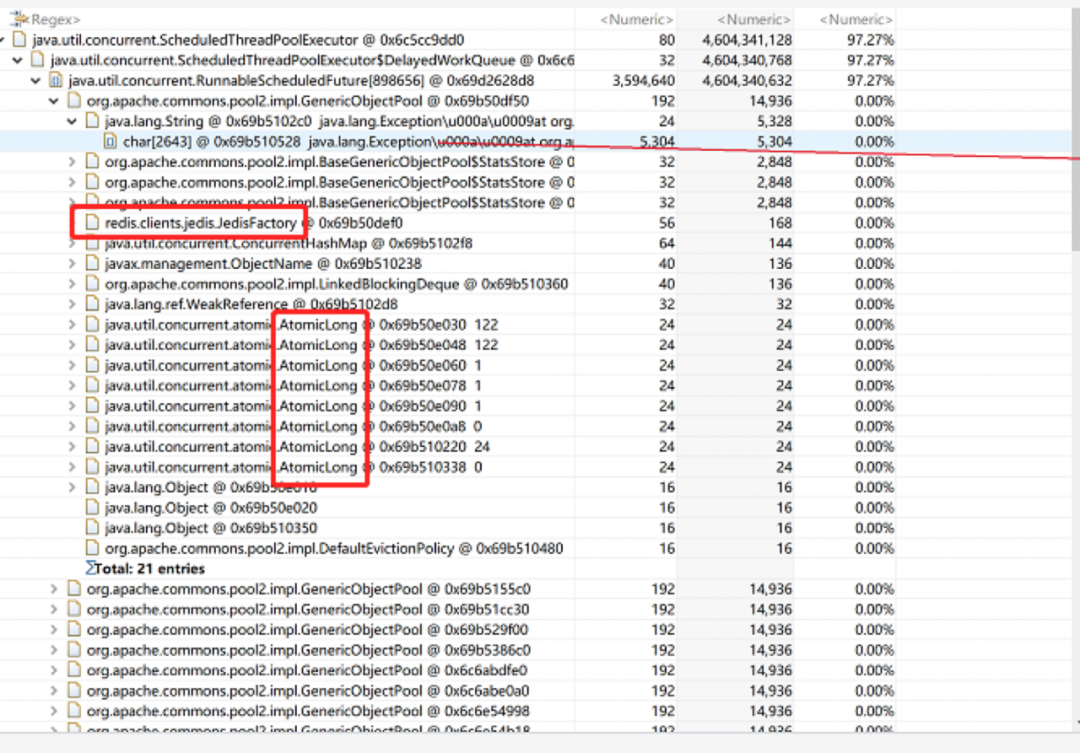
之前通过jmap分析排行在前的AtomicLong(排第一,占2.7G)和redisFactory类都是躲藏在GenericObjectPool对象中的。分析至此,本人的第六撸感告诉我,离事情的真相越来越近了。与redis连接相关的GenericObjectPool对象就是问题的真凶,内存泄漏的对象。
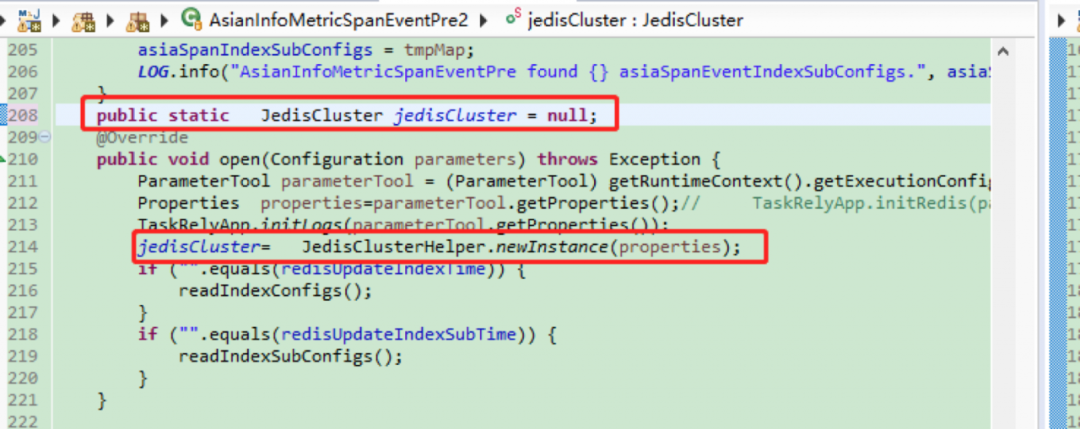
1. 连接池加锁
由于去掉和redis的连接池未解决问题,依然生成大量GenericObjectPool对象不释放,一个推测是并发原因导致单例没有生效,生成了很多个JedisCluster对象,而JedisCluster对象包含了连接池。尝试synchronized加锁:
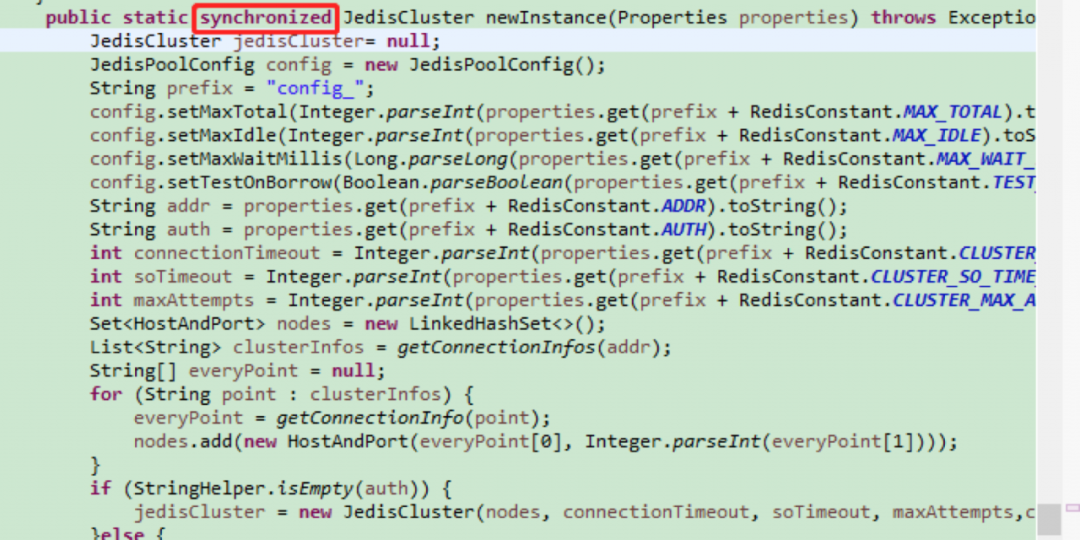
结果:问题仍未缓解,仍未解决,还得继续。
2. 改redisCluseter对象为单独变量
上两步都没有进展,从头开始分析代码,代码分析过程中发现flink十多个任务都是使用统一的redis初始化方法且只生成单个redis连接实例。十多个flink任务, 每个flink任务中又有许多地方需要用到redis连接,redis单例在这里就会成为瓶颈(数据处理不过来,进而积压)。于是变单例的redisCluseter对象为单独变量,每个用到redis连接的类都生成redisCluseter变量,然后再与redis交互,以此使redis随Flink的连接数并发派生。
整改结果:问题得到阶段性解决,之前运行一天就出现堆和gc问题,整改后稳定运行三天后又出现同样问题。
4. 去掉异步方法
虽然只稳定运行三天,但对笔者和整个团队来说,也还是很开心的,说明我们的方向大概率是对的。但问题复现,作为四有好青年的IT民工,咱得发扬不怕苦,不怕累的精神继续分析排查。这次排查过程中发现众多的GenericObjectPool是由ScheduledThreadPoolExector引用的,ScheduledThreadPoolExector是一个异步类,再排查flink中的异步方法。找到AsyncDataStream.unorderedWait()是异步写入redis方法,将其修改为改造后的官方flink-redis连接包,去除异步。
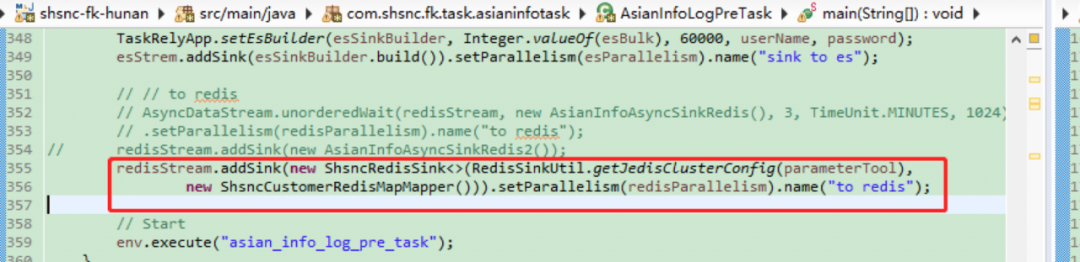
结果:问题解决,堆和gc一直正常