[TOC]

慢查询日志
slow_query_log :是否开启慢查询日志,1表示开启,0表示关闭。
long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志。
1 | show variables like 'slow_query%';//慢查询日志是否开启 |
在MySQL里面执行下面SQL语句,然后我们去检查对应的慢查询日志,就会发现类似下面这样的信息。
1 | mysql> select sleep(3); |

Rows_examined显示扫描了50000行

Show processList
state 一般取值为休眠(sleep),查询(query)连接(connect)等
Waiting for table metadata lock
,现在有一个线程正在表t上请求或者持有MDL写锁

Show profile
进一步查询,开启了show profile的话会记录你查询过的语句
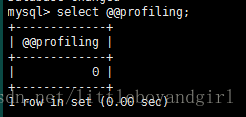
查看是否打开了性能分析功能
1
select @@profiling;1
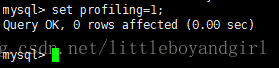
打开 profiling 功能
1
set profiling=1;1
执行sql语句
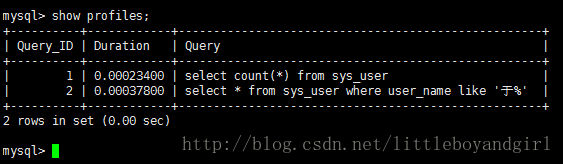
执行 show profiles 查看分析列表
查询第二条语句的执行情况
1
show profile[cpu/memory] for query 2;1
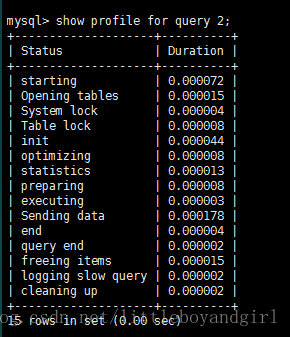
Status : sql 语句执行的状态
Duration: sql 执行过程中每一个步骤的耗时
CPU_user: 当前用户占有的 cpu
CPU_system: 系统占有的 cpu
Block_ops_in : I/O 输入
Block_ops_out : I/O 输出
status的相关字段
Sorting result
正在对结果进行排序,类似Creating sort index,不过是正常表,而不是在内存表中进行排序。
建议:创建适当的索引
- Table lock
表级锁,没什么好说的,要么是因为MyISAM引擎表级锁,要么是其他情况显式锁表
- create sort index
当前的SELECT中需要用到临时表在进行ORDER BY排序
建议:创建适当的索引
- Creating tmp table
创建临时表。先拷贝数据到临时表,用完后再删除临时表。消耗内存,数据来回拷贝删除,消耗时间,
建议:优化索引
explain
id
是一组数字,代表多个表之间的查询顺序,或者包含子句查询语句中的顺序,id 总共分为三种情况,依次详解
- id 相同,执行顺序由上至下
- id 不同,如果是子查询,id 号会递增,id 值越大优先级越高,越先被执行
- id 相同和不同的情况同时存在
select_type
查询类型,有简单查询、联合查询、子查询等
| 类型 | 描述 |
|---|---|
| SIMPLE | 简单的select查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子部分,最外层查询则被标记为 |
| SUBQUERY | 在SELECT或WHERE列表中包含了子查询 |
| DERIVED(衍生) | 在FROM列表中包含的子查询被标记为DERIVED(衍生). MySQL会递归执行这些子查询, 把结果放在临时表里。 |
| UNION | 若第二个SELECT出现在UNION之后,则被标记为UNION |
| UNION RESULT | 从UNION表获取结果的SELECT |
(考虑)
type:
对表访问方式
NULL>system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
System与 const
说明:
System:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
const:通常情况下,如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。至于如何转化以及何时转化,这个取决于优化器。
脚本:
1 | mysql> explain select * from users where userid=1; |
eq_ref
说明:
对前面的表中每一行记录的组合,都从当前表中读取一行。
脚本:
1 | explain |
执行结果:
ref
说明:
从当前表中读取所有匹配索引值的行。
脚本:
1 | explain |
执行结果:
Range
说明:
- 只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引
- 一般就是在你的where语句中出现了between、<、>、in等的查询
- 这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
脚本:
1 | explain |
执行结果:
index
Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常为ALL块,应为索引文件通常比数据文件小。(Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取)

ALL
Full Table Scan,遍历全表以找到匹配的行

key_len列
说明:
Key_len表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好key_len显示的值为索引字段的最大可能长度,并非实际使用长度
Rows 列
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数.
1 | explain |
执行结果:
Extra 列
filesort只能应用在单个表上,如果有多个表的数据需要排序,那么MySQL会先使用using temporary保存临时数据,然后再在临时表上使用filesort进行排序,最后输出结果。
包含不适合在其它列中显示但十分重要的额外信息
| 值 | 描述 |
|---|---|
| Using filesort | 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为”文件排序” |
| Using temporary | 使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。 |
| Using index | 表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错! 如果同时出现using where,表明索引被用来执行索引键值的查找; 如果没有同时出现using where,表明索引用来读取数据而非执行查找动作 |
| Using where | 使用了where条件 |
| Using join buffer | 使用了连接缓存 |
| impossible where | where子句的值总是false,不能用来获取任何元素 |
| distinct | 一单mysql找到了与形相联合匹配的行,就不在搜索了 |
Using filesort
说明:
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
MySQL中无法利用索引完成的排序操作称为“文件排序”
当发现有Using filesort 后,实际上就是发现了可以优化的地方
脚本:
1 | explain |
执行结果:
解说:
上图其实是一种索引失效的情况,后面会讲,可以看出查询中用到了个联合索引,索引分别为actor_id,film_id
Using temporary
说明:
使用了临时表保存中间结果,MySQL在对结果排序时使用临时表,常见于排序order by 和分组查询group by
脚本:
1 | explain |
执行结果:
解说:
尤其发现在执行计划里面有using filesort而且还有Using temporary的时候,特别需要注意
Using index
说明:
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找
脚本:
1 | explain |
执行结果:
如果没有同时出现using where,表明索引用来读取数据而非执行查找动作
优化数据访问
- 切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要
的查询。 - 分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查
询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
减少锁竞争;
在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进
行查询,这可能比随机的连接要更高效。
索引优化
- 减少请求的数据量
只返回必要的列:最好不要使用 SELECT * 语句。
只返回必要的行:使用 LIMIT 语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存
带来的查询性能提升将会是非常明显的。 - 减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
应该做的原则:
联合索引最左前缀原则
复合索引遵守「最左前缀」原则,查询条件中,使用了复合索引前面的字段,索引才会被使用,如果不是按照索引的最左列开始查找,则无法使用索引。
比如在(a,b,c)三个字段上建立联合索引,那么它能够加快a|(a,b)|(a,b,c)三组查询的速度,而不能加快b|(b,a)这种查询顺序。
另外,建联合索引的时候,区分度最高的字段在最左边。
使用覆盖索引
所谓覆盖索引,是指被查询的列,数据能从索引中取得,而不用通过行定位符再到数据表上获取,能够极大的提高性能。
可以定义一个让索引包含的额外的列,即使这个列对于索引而言是无用的。
范围列可以用到索引
范围条件有:<、<=、>、>=、between等。
范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引。
如果出现了filesort
order by也是遵循索引原则的,使用索引进行排序
不应该做的原则:
不要在列上使用函数和进行运算
不要在列上使用函数,这将导致索引失效而进行全表扫描。
例如下面的 SQL 语句:
1 | select * from artile where YEAR(create_time) <= '2018'; |
即使 date 上建立了索引,也会全表扫描,可以把计算放到业务层,这样做不仅可以节省数据库的 CPU,还可以起到查询缓存优化效果。
负向条件查询不能使用索引
负向条件有:!=、<>、not in、not exists、not like 等。
1 | select * from artile where status != 1 and status != 2; |
可以使用in进行优化:
1 | select * from artile where status in (0,3) |
更新频繁、数据区分度不高的字段上不宜建立索引
更新会变更B+树,更新频繁的字段建立索引会大大降低数据库性能。
「性别」这种区分度不大的属性,建立索引没有意义,不能有效过滤数据,性能与全表扫描类似。
区分度可以使用 count(distinct(列名))/count(*) 来计算,在80%以上的时候就可以建立索引。
索引列不允许为null
单列索引不存null值,复合索引不存全为null的值,如果列允许为 null,可能会得到不符合预期的结果集。
避免使用or来连接条件
应该尽量避免在 where 子句中使用 or 来连接条件,因为这会导致索引失效而进行全表扫描,虽然新版的MySQL能够命中索引,但查询优化耗费的 CPU比in多。
模糊查询
前导模糊查询不能使用索引,非前导查询可以。
分库分表
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
分布式ID
分布式事务
explain 每个列代表什么含义(关于优化级别 ref 和 all,什么时候应该用到index却没用到,关于extra列出现了usetempory 和 filesort分别的原因和如何着手优化等)
show profile 怎么使用。