[TOC]
Spring IoC
Q1:IoC 是什么?
ioc,控制反转。平时传统方式中,当我们需要使用对象的时候,我们就必须自己手动地去创建,比如直接new一个对象。这样当我们在项目中需要使用大量对象时,就显得特别繁琐。 创建对象的控制权进行转移到IOC容器
通过ioc就可以解决这些问题,我们不用再自己去手动new对象了,我们只需要设置好配置信息,ioc容器就可以帮我们自动创建对象,并且进行依赖注入,对这些对象进行管理。当我们在需要相应对象时,直接去ioc容器里面获取即可。
1 | 就是将依赖对象的创建和绑定转移到被依赖对象类的外部来实现 |
Q2:IoC 容器初始化过程?
基于 XML 的容器初始化
为了方便理解和追踪代码,使用常用实现类ClassPathXmlApplicationContext写了一个小例子,步骤如下:
1).在类路径下新建xml,定义一个bean,其中daoImpl就是bean的名字,spring.aop.xml.dao.impl.DaoImpl对应具体的一个pojo.
1 | <bean id="daoImpl" class="spring.aop.xml.dao.impl.DaoImpl" /> |
2).main方法中直接载入xml,然后获取bean,最后执行bean实例的方法。
1 | 1 public static void main(String[] args) { |
下面我们就分析ClassPathXmlApplicationContext源码,来看看都做了什么。
ClassPathXmlApplicationContext类图

1 | DefaultResourceLoader,该类设置classLoader,并且将配置文件 封装为Resource文件。 |
1 | 当创建一个 ClassPathXmlApplicationContext 时,构造方法做了两件事:① 调用父容器的构造方法为容器设置好 Bean 资源加载器。② 调用父类的 `setConfigLocations` 方法设置 Bean 配置信息的定位路径。 |
refresh()方法,其实标志容器初始化过程的正式启动.
refresh 是一个模板方法,规定了 IoC 容器的启动流程, 在创建 IoC 容器前如果已有容器存在,需要把已有的容器销毁,保证在 refresh 方法后使用的是新创建的 IoC 容器。
容器创建后通过 loadBeanDefinitions 方法加载 Bean 配置资源。加载资源时首先解析配置文件路径,读取内容,然后通过 XML 解析器将 Bean 配置信息转换成文档对象,并对文档对象进行解析。
1 | BeanDefinition: |
Spring IoC 容器中解析注册的 Bean 信息存放在一个 HashMap 集合中,在refresh过程中需要使用 synchronized 保证线程安全。当配置信息中配置的 Bean 被解析且被注册到 IoC 容器中后,初始化就算真正完成了.
1 | Bean 定义信息已经可以使用且可被检索。Spring IoC 容器的作用就是对这些注册的 Bean 定义信息进行处理和维护,注册的 Bean 定义信息是控制反转和依赖注入的基础。(key 是字符串,值是 BeanDefinition) |
1 | public void refresh() throws BeansException, IllegalStateException { |
1 | DefaultListableBeanFactory |
基于注解的容器初始化
分为两种:① 直接将注解 Bean 注册到容器中。② 通过扫描指定的包及其子包的所有类处理,在初始化注解容器时指定要自动扫描的路径。
Q3:依赖注入的实现方法有哪些?(和IOC的区别)
(控制反转:创建对象实例的控制从代码控制剥离到IOC容器控制,实际就是你在xml文件shu控制,侧重于原理。
依赖注入:创建对象实例时,为这个对象注入属性值或其它对象实例,侧重于实现。)
它提供一种机制,将需要依赖(低层模块)对象的引用传递给被依赖(高层模块)对象
构造方法注入: 构造函数注入可以通过配置文件的方法注入和不通过配置文件
配置文件,XML。
setter 方法注入: 当前对象只需要为其依赖对象对应的属性添加 setter 方法,就可以通过 setter 方法将依赖对象注入到被依赖对象中。setter 方法注入在描述性上要比构造方法注入强,并且可以被继承,允许设置默认值。缺点是无法在对象构造完成后马上进入就绪状态。
接口注入: 必须实现某个接口,接口提供方法来为其注入依赖对象。使用少,因为它强制要求被注入对象实现不必要接口,侵入性强。
具体思路是先定义一个接口,包含一个设置依赖的方法。
Q4:依赖注入的相关注解?
@Autowired:自动按类型注入,如果有多个匹配,查找不到会报错。
@Qualifier:在自动按照类型注入的基础上再按照 Bean 的 id 注入,给变量注入时必须搭配 @Autowired,给方法注入时可单独使用。
@Resource :直接按照 Bean 的 id 注入,只能注入 Bean 类型。
@Value :用于注入基本数据类型和 String 类型。
@Autowired 是通过 byType 的方式去注入的, 使用该注解,要求接口只能有一个实现类。
@Resource 可以通过 byName 和 byType的方式注入, 默认先按 byName的方式进行匹配,如果匹配不到,再按 byType的方式进行匹配。 @Resource(name=”dogImpl”)
1 | @Service("dogImpl") |
1 | @RequestMapping:用于处理请求url映射的注解,可用于类或方法上。用于类上,则表示类中的所有 |
Q5:依赖注入的过程?
依赖注入(Dependency Injection,简称 DI)是实现控制反转的主要方式
作者:沉默王二
链接:https://zhuanlan.zhihu.com/p/77036617
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1)基于构造函数。实现特定参数的构造函数,在新建对象时传入所依赖类型的对象。
老王类的代码修改如下所示:
1 | public class Laowang { |
测试类的代码修改如下所示:
1 | public class Test { |
这时候,控制权掌握在测试类的手里,它决定派小二和尚还是小三和尚去执行老王的扫地命令。
2)基于 set 方法。实现特定属性的 public set 方法,让外部容器调用传入所依赖类型的对象。
老王类的代码修改如下所示:
1 | public class Laowang { |
测试类的代码修改如下所示:
1 | public class Test { |
这时候,控制权仍然掌握在测试类的手里,它决定派小二和尚还是小三和尚去执行老王的扫地命令。
3)基于接口。
作者:沉默王二
链接:https://zhuanlan.zhihu.com/p/77036617
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Spring 框架
当我们搞清楚控制反转和依赖注入的概念后,就可以顺带了解一下大名鼎鼎的 Spring 框架。控制反转是 Spring 框架的核心,贯穿始终。Spring 中依赖注入有两种实现方式:set 方式(传值方式)和构造器方式(引用方式)。
首先,我们需要在 pom.xml 文件中加入 Spring 的依赖项,代码如下所示:
1 | <dependency> |
其次,我们将 Laowang 类修改为如下内容:
1 | public class Laowang { |
然后,我们创建一个 Spring 的配置文件 application.xml,内容如下所示:
1 | <?xml version="1.0" encoding="UTF-8"?> |
通过 元素配置了两个对象,一个老王主持,一个小三和尚,使用 元素将小三和尚作为老王主持的构造参数。
准备工作完成以后,我们来测试一下,代码示例如下:
1 | public class Test { |
你看,我们将控制权交给了 IoC 框架 Spring,这样也可以完美的解决代码耦合度较紧的问题。
Q6:Bean 的生命周期?
- 实例化bean对象(通过构造方法或者工厂方法)
- 设置对象属性(setter等)(依赖注入)
- 检查Aware接口
- 将Bean实例传递给Bean的前置处理器的postProcessBeforeInitialization(Object bean, String beanname)方法
- 调用Bean的初始化方法
- 将Bean实例传递给Bean的后置处理器的postProcessAfterInitialization(Object bean, String beanname)方法
- 使用Bean
- 当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean接口,会调用其实现的destroy方法

经过这一系列初始化操作后 Bean 达到可用状态,接下来就可以使用 Bean 了,当使用完成后会调用 destroy 方法进行销毁,此时也可以指定自定义的销毁方法,最终 Bean 被销毁且从容器中移除。
XML 方式通过配置 bean 标签中的 init-Method 和 destory-Method 指定自定义初始化和销毁方法。
注解方式通过 @PreConstruct 和 @PostConstruct 注解指定自定义初始化和销毁方法。
Q7:Bean 的作用范围?(不用管了)
通过 scope 属性指定 bean 的作用范围,包括:
① singleton:单例模式,是默认作用域,不管收到多少 Bean 请求每个容器中只有一个唯一的 Bean 实例。
② prototype:原型模式,和 singleton 相反,每次 Bean 请求都会创建一个新的实例。
Q8:如何通过 XML 方式创建 Bean?
默认无参构造方法,只需要指明 bean 标签中的 id 和 class 属性,如果没有无参构造方报错。
Q9:如何通过注解创建 Bean?
@Component 把当前类对象存入 Spring 容器中,相当于在 xml 中配置一个 bean 标签。value 属性指定 bean 的 id,默认使用当前类的首字母小写的类名。
@Controller,@Service,@Repository 三个注解都是 @Component 的衍生注解,作用及属性都是一模一样的。只是提供了更加明确语义,@Controller 用于表现层,@Service用于业务层,@Repository用于持久层。如果注解中有且只有一个 value 属性要赋值时可以省略 value。
如果想将第三方的类变成组件又没有源代码,也就没办法使用 @Component 进行自动配置,这种时候就要使用 @Bean 注解。被 @Bean 注解的方法返回值是一个对象,将会实例化,配置和初始化一个新对象并返回,这个对象由 Spring 的 IoC 容器管理。name 属性用于给当前 @Bean 注解方法创建的对象指定一个名称,即 bean 的 id。当使用注解配置方法时,如果方法有参数,Spring 会去容器查找是否有可用 bean对象,查找方式和 @Autowired 一样。
Q10:如何通过注解配置文件?
@Configuration 用于指定当前类是一个 spring 配置类,当创建容器时会从该类上加载注解,value 属性用于指定配置类的字节码。
1 | package config; |
1 | public class TestMain { |
@ComponentScan 用于指定 Spring 在初始化容器时要扫描的包。basePackages 属性用于指定要扫描的包。
1 | `@PropertySource` 用于加载 `.properties` 文件中的配置。value 属性用于指定文件位置,如果是在类路径下需要加上 classpath。 |
Q11:BeanFactory、FactoryBean 和 ApplicationContext 的区别?
BeanFactory 是一个 Bean 工厂,是一个接口,作用是管理 Bean,包括实例化、配置对象及建立这些对象间的依赖。BeanFactory 实例化后并不会自动实例化 Bean,只有当 Bean 被使用时才实例化与装配依赖关系,属于延迟加载,适合多例模式。
ApplicationConext 是 BeanFactory 的子接口,扩展了 BeanFactory 的功能。BeanFactory在启动的时候不会去实例化Bean,
- ApplicationContext在启动的时候就把所有的Bean全部实例化了。
- 资源访问,如URL和文件
- AOP(拦截器)
FactoryBean 是一个工厂 Bean,是一个能生产或者修饰对象生成的工厂Bean
Q13: Spring启动过程

1 | <context-param> |
1 | spring的启动其实就是IOC容器的启动过程,通过上述的第一段配置`<context-param>`是初始化上下文,然后通过后一段的的<listener>来加载配置文件,其中调用的spring包中的`ContextLoaderListener`这个上下文监听器,`ContextLoaderListener`是一个实现了`ServletContextListener`接口的监听器,他的父类是 `ContextLoader`,在启动项目时会触发`contextInitialized`上下文初始化方法。下面我们来看看这个方法: |
调用refresh
Q15: Spring如何解决循环依赖(三级缓存)(必考)
Q17: Spring的@Transactional如何实现的(必考)
Q18: Spring的事务传播级别
Q19: 拦截器,监听器和过滤器区别
拦截器依赖于SpringMVC框架。在实现上基于Java的反射机制,属于面向切面编程(AOP)面向切面编程的一种运用。
过滤器实际上就是对web资源进行拦截,做一些处理后再交给下一个过滤器或servlet处理通常都是用来拦截request进行处理的,也可以对返回的response进行拦截处理
多个Filter按照字母进行排序
1 | package filter; |

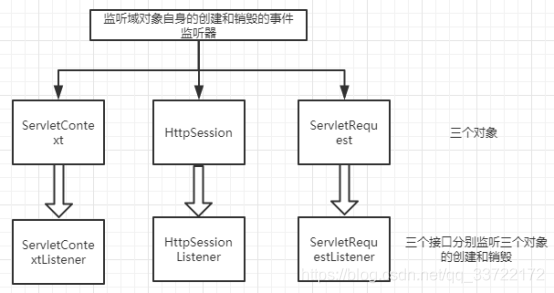
监听器
ServletContext,HttpSession,ServletRequest
1)ServletContext对应监控application内置对象的创建跟销毁.
2)用于监听用户会话对象(HttpSession)的事件监听器
3)用于监听请求消息对象(ServletRequest)的事件监听器
Q20: Springboot起步依赖有什么好处?
Q21:Spring 框架中都用到了哪些设计模式?
Spring 框架中使用到了大量的设计模式,下面列举了比较有代表性的:
(1)工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例;
BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象
(2)单例模式:Bean默认为单例模式。
(3)代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术;
(4)模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
(5)观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中listener的实现–ApplicationListener。
Spring和SpringBoot的区别?
Spring AOP
Q1:AOP 是什么?
AOP 即面向切面编程,简单地说就是将代码中重复的部分抽取出来,在需要执行的时候使用动态代理技术,在不修改源码的基础上对方法进行增强。用于处理系统中分布于各个模块的横切关注点,比如事务管理、日志、缓存等等
Spring 根据类是否实现接口来判断动态代理方式,如果实现接口会使用 JDK 的动态代理,核心是 InvocationHandler 接口和 Proxy 类,如果没有实现接口会使用 CGLib 动态代理,CGLib 是在运行时动态生成某个类的子类,如果某个类被标记为 final,不能使用 CGLib 。
JDK 动态代理主要通过重组字节码实现,首先获得被代理对象的引用和所有接口,生成新的类必须实现被代理类的所有接口,动态生成Java 代码后编译新生成的 .class 文件并重新加载到 JVM 运行。JDK 代理直接写 Class 字节码,CGLib 是采用 ASM 框架写字节码,生成代理类的效率低。但是 CGLib 调用方法的效率高,因为 JDK 使用反射调用方法,CGLib 使用 FastClass 机制为代理类和被代理类各生成一个类,这个类会为代理类或被代理类的方法生成一个 index,这个 index 可以作为参数直接定位要调用的方法。
常用场景包括权限认证、自动缓存、错误处理、日志、调试和事务等。
Q2:AOP 的相关注解有哪些?
1 | @Aspect |
@Aspect:声明被注解的类是一个切面 Bean。
@Before:前置通知,指在某个连接点之前执行的通知。
@After:后置通知,指某个连接点退出时执行的通知(不论正常返回还是异常退出)。
@AfterReturning:返回后通知,指某连接点正常完成之后执行的通知,返回值使用returning属性接收。
@AfterThrowing:异常通知,指方法抛出异常导致退出时执行的通知,和@AfterReturning只会有一个执行,异常使用throwing属性接收。
Q3:AOP 的相关术语有什么?
Aspect:切面,一个关注点的模块化,这个关注点可能会横切多个对象。
Joinpoint:连接点,程序执行过程中的某一行为,即业务层中的所有方法。。
Advice:通知,指切面对于某个连接点所产生的动作,包括前置通知、后置通知、返回后通知、异常通知和环绕通知。
Pointcut:切入点,指被拦截的连接点,切入点一定是连接点,但连接点不一定是切入点。
Proxy:代理,Spring AOP 中有 JDK 动态代理和 CGLib 代理,目标对象实现了接口时采用 JDK 动态代理,反之采用 CGLib 代理。
Target:代理的目标对象,指一个或多个切面所通知的对象。
Weaving :所谓织入就是在切点的引导下,将通知逻辑插入到方法调用上,使得我们的通知逻辑在方法调用时得以执行。
Q4:AOP 的过程?
Spring AOP 由 BeanPostProcessor 后置处理器开始,这个后置处理器是一个***,可以监听容器触发的 Bean 生命周期事件,向容器注册后置处理器以后,容器中管理的 Bean 就具备了接收 IoC 容器回调事件的能力。BeanPostProcessor 的调用发生在 Spring IoC 容器完成 Bean 实例对象的创建和属性的依赖注入后,为 Bean 对象添加后置处理器的入口是 initializeBean 方法。
Spring 中 JDK 动态代理通过 JdkDynamicAopProxy 调用 Proxy 的 newInstance 方法来生成代理类,JdkDynamicAopProxy 也实现了 InvocationHandler 接口,invoke 方法的具体逻辑是先获取应用到此方法上的拦截器链,如果有拦截器则创建 MethodInvocation 并调用其 proceed 方法,否则直接反射调用目标方法。因此 Spring AOP 对目标对象的增强是通过拦截器实现的。
Spring MVC
Q1:Spring MVC 的处理流程?
Web 容器启动时会通知 Spring 初始化容器,加载 Bean 的定义信息并初始化所有单例 Bean,然后遍历容器中的 Bean,获取每一个 Controller 中的所有方法访问的 URL,将 URL 和对应的 Controller 保存到一个 Map 集合中。
所有的请求会转发给 DispatcherServlet 前端处理器处理,DispatcherServlet 会请求 HandlerMapping 找出容器中被 @Controler 注解修饰的 Bean 以及被 @RequestMapping 修饰的方法和类,生成 Handler 和 HandlerInterceptor 并以一个 HandlerExcutionChain 处理器执行链的形式返回。
之后 DispatcherServlet 使用 Handler 找到对应的 HandlerApapter,通过 HandlerApapter 调用 Handler 的方法,将请求参数绑定到方法的形参上,执行方法处理请求并得到 ModelAndView。
最后 DispatcherServlet 根据使用 ViewResolver 试图解析器对得到的 ModelAndView 逻辑视图进行解析得到 View 物理视图,然后对视图渲染,将数据填充到视图中并返回给客户端。
Q2:Spring MVC 有哪些组件?
DispatcherServlet:SpringMVC 中的前端控制器,是整个流程控制的核心,负责接收请求并转发给对应的处理组件。
Handler:处理器,完成具体业务逻辑,相当于 Servlet 或 Action。
HandlerMapping:完成 URL 到 Controller 映射,DispatcherServlet 通过 HandlerMapping 将不同请求映射到不同 Handler。
HandlerInterceptor:处理器拦截器,是一个接口,如果需要完成一些拦截处理,可以实现该接口。
HandlerExecutionChain:处理器执行链,包括两部分内容:Handler 和 HandlerInterceptor。
HandlerAdapter:处理器适配器,Handler执行业务方法前需要进行一系列操作,包括表单数据验证、数据类型转换、将表单数据封装到JavaBean等,这些操作都由 HandlerAdapter 完成。DispatcherServlet 通过 HandlerAdapter 来执行不同的 Handler。
ModelAndView:装载模型数据和视图信息,作为 Handler 处理结果返回给 DispatcherServlet。
ViewResolver:视图解析器,DispatcherServlet 通过它将逻辑视图解析为物理视图,最终将渲染的结果响应给客户端。
Q3:Spring MVC 的相关注解?
@Controller:在类定义处添加,将类交给IoC容器管理。
@RequtestMapping:将URL请求和业务方法映射起来,在类和方法定义上都可以添加该注解。value 属性指定URL请求的实际地址,是默认值。method 属性限制请求的方法类型,包括GET、POST、PUT、DELETE等。如果没有使用指定的请求方法请求URL,会报405 Method Not Allowed 错误。params 属性限制必须提供的参数,如果没有会报错。
@RequestParam:如果 Controller 方法的形参和 URL 参数名一致可以不添加注解,如果不一致可以使用该注解绑定。value 属性表示HTTP请求中的参数名。required 属性设置参数是否必要,默认false。defaultValue 属性指定没有给参数赋值时的默认值。
@PathVariable:Spring MVC 支持 RESTful 风格 URL,通过 @PathVariable 完成请求参数与形参的绑定。
Q5:mybatis的xml有什么标签?
Mybatis
Q1:Mybatis 的优缺点?
优点
相比 JDBC 减少了大量代码量,减少冗余代码。
使用灵活,SQL 语句写在 XML 里,从程序代码中彻底分离,降低了耦合度,便于管理。
提供 XML 标签,支持编写动态 SQL 语句。
提供映射标签,支持对象与数据库的 ORM 字段映射关系。
缺点
SQL 语句编写工作量较大,尤其是字段和关联表多时。
SQL 语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
Q2:Mybatis 的 XML 文件有哪些标签属性?
select、insert、update、delete 标签分别对应查询、添加、更新、删除操作。
parameterType 属性表示参数的数据类型,包括基本数据类型和对应的包装类型、String 和 Java Bean 类型,当有多个参数时可以使用 #{argn} 的形式表示第 n 个参数。除了基本数据类型都要以全限定类名的形式指定参数类型。
resultType 表示返回的结果类型,包括基本数据类型和对应的包装类型、String 和 Java Bean 类型。还可以使用把返回结果封装为复杂类型的 resultMap 。
Q3:Mybatis 的一级缓存是什么?
一级缓存是 SqlSession 级别,默认开启且不能关闭。
操作数据库时需要创建 SqlSession 对象,对象中有一个 HashMap 存储缓存数据,不同 SqlSession 之间缓存数据区域互不影响。
一级缓存的作用域是 SqlSession 范围的,在同一个 SqlSession 中执行两次相同的 SQL 语句时,第一次执行完毕会将结果保存在缓存中,第二次查询直接从缓存中获取。
如果 SqlSession 执行了 DML 操作(insert、update、delete),Mybatis 必须将缓存清空保证数据有效性。
Q4:Mybatis 的二级缓存是什么?
二级缓存是Mapper 级别,默认关闭。
使用二级缓存时多个 SqlSession 使用同一个 Mapper 的 SQL 语句操作数据库,得到的数据会存在二级缓存区。作用域是 Mapper 的同一个 namespace,不同 SqlSession 两次执行相同的 namespace 下的 SQL 语句,参数也相等,则第一次执行成功后会将数据保存在二级缓存中,第二次可直接从二级缓存中取出数据。同样使用 HashMap 进行数据存储,相比于一级缓存,二级缓存范围更大,多个 SqlSession 可以共用二级缓存。
要使用二级缓存,需要在全局配置文件中配置 <setting name="cacheEnabled" value="true"/> ,再在对应的映射文件中配置一个 <cache/> 标签。
Q5:Mybatis #{} 和 ${} 的区别?
使用 ${} 相当于使用字符串拼接,存在 SQL 注入的风险。
使用 #{} 相当于使用占位符,可以防止 SQL 注入,不支持使用占位符的地方就只能使用 ${} ,典型情况就是动态参数。
首先,我们说一下这两种引用参数时的区别,使用#{parameterName}引用参数的时候,Mybatis会把这个参数认为是一个字符串,并自动加上’’,例如传入参数是“Smith”,那么在下面SQL中:
1 | Select * from emp where name = #{employeeName} |
使用的时候就会转换为:
1 | Select * from emp where name = 'Smith'; |
同时使用${parameterName}的时候在下面SQL中
1 | Select * from emp where name = ${employeeName} |
就会直接转换为:
1 | Select * from emp where name = Smith |
简单说#{}是经过预编译的,是安全的。
而${}是未经过预编译的,仅仅是取变量的值,是非安全的,存在SQL注入。
注解
@resource与 @autowired
1 | 没错,注解的本质就是一个继承了 Annotation 接口的接口。 |
Springboot
Spring Boot启动流程以及生命周期

https://blog.csdn.net/u011277123/article/details/104476683
.Spring和Springboot的区别
Spring Boot基本上是Spring框架的扩展,它消除了设置Spring应用程序所需的XML配置,为更快,更高效的开发生态系统铺平了道路。提供的starters 简化构建配置
Spring Boot为不同的Spring模块提供了许多依赖项。一些最常用的是:spring-boot-starter-data-jpaspring-boot-starter-securityspring-boot-starter-testspring-boot-starter-webspring-boot-starter-thymeleaf
Springboot starter
不使用springboot时,需要引入spring-web、spring-webmvc、spring-aop等等来支持项目开发
1 | Spring等方式 |
其他
RESTful 和SOAP
SOA和微服务的区别
springboot的优点
Spring Data JPA
Q1:ORM 是什么?
ORM 即 Object-Relational Mapping ,表示对象关系映射,映射的不只是对象的值还有对象之间的关系,通过 ORM 就可以把对象映射到关系型数据库中。操作实体类就相当于操作数据库表,可以不再重点关注 SQL 语句。
Q2:JPA 如何使用?
只需要持久层接口继承 JpaRepository 即可,泛型参数列表中第一个参数是实体类类型,第二个参数是主键类型。
运行时通过 JdkDynamicAopProxy 的 invoke 方法创建了一个动态代理对象 SimpleJpaRepository,SimpleJpaRepository 中封装了 JPA 的操作,通过 hibernate(封装了JDBC)完成数据库操作。
Q3:JPA 实体类相关注解有哪些?
@Entity:表明当前类是一个实体类。
@Table :关联实体类和数据库表。
@Column :关联实体类属性和数据库表中字段。
@Id :声明当前属性为数据库表主键对应的属性。
@GeneratedValue: 配置主键生成策略。
@OneToMany :配置一对多关系,mappedBy 属性值为主表实体类在从表实体类中对应的属性名。
@ManyToOne :配置多对一关系,targetEntity 属性值为主表对应实体类的字节码。
@JoinColumn:配置外键关系,name 属性值为外键名称,referencedColumnName 属性值为主表主键名称。
Q4:对象导航查询是什么?
通过 get 方法查询一个对象的同时,通过此对象可以查询它的关联对象。
对象导航查询一到多默认使用延迟加载的形式, 关联对象是集合,因此使用立即加载可能浪费资源。
对象导航查询多到一默认使用立即加载的形式, 关联对象是一个对象,因此使用立即加载。
如果要改变加载方式,在实体类注解配置加上 fetch 属性即可,LAZY 表示延迟加载,EAGER 表示立即加载。
外置的Tomcat和SpringBoot的tomcat有什么区别
1.tomcat禁用AJP?我启动了个springboot项目,发现并没有开启AJP,同时用的是nio模式
1 | ajp13是一个二进制的TCP传输协议,相比HTTP这种纯文本的协议来说,效率和性能更高,也做了很多优化。显然,浏览器并不能直接支持AJP13协议,只支持HTTP协议。 |

2.内置的tomcat可以用main跑项目,而如果要用外置的tomcat就需要把项目打成war包,然后拷贝到webapp下进行运行
SpringBoot 怎么调起Tomcat?
https://blog.csdn.net/qq_32101993/article/details/99700910
SpringBoot 的启动是通过 new SpringApplication()实例来启动的,启动过程主要做如下几件事情:> 1. 配置属性 > 2. 获取监听器,发布应用开始启动事件 > 3. 初始化输入参数 > 4. 配置环境,输出 banner > 5. 创建上下文 > 6. 预处理上下文 > 7. 刷新上下文 > 8. 再刷新上下文 > 9. 发布应用已经启动事件 > 10. 发布应用启动完成事件
而启动 Tomcat 就是在第 7 步中“刷新上下文”;Tomcat 的启动主要是初始化 2 个核心组件,连接器(Connector)和容器(Container),一个 Tomcat 实例就是一个 Server,一个 Server 包含多个 Service,也就是多个应用程序,每个 Service 包含多个连接器(Connetor)和一个容器(Container),而容器下又有多个子容器,按照父子关系分别为:Engine,Host,Context,Wrapper,其中除了 Engine 外,其余的容器都是可以有多个。
Tomcat 主要包含了 2 个核心组件,连接器(Connector)和容器(Container),用图表示如下:
一个 Tomcat 是一个 Server,一个 Server 下有多个 service,也就是我们部署的多个应用,一个应用下有多个连接器(Connector)和一个容器(Container),容器下有多个子容器,关系用图表示如下:
Engine 下有多个 Host 子容器,Host 下有多个 Context 子容器,Context 下有多个 Wrapper 子容器。
Tomcat的设计模式
责任链模式
整个Http请求被处理的流程:
请求被Connector组件接收,创建Request和Response对象。
Connector将Request和Response交给Container,先通过Engine的pipeline组件流经内部的每个Valve。
请求流转到Host的pipeline组件中,并且经过内部Valve的过滤。
请求流转到Context的pipeline组件中,并且经过内部的Valve的过滤。
请求流转到Wrapper的pipeline组件中,并且经过内部的Valve的过滤。
Wrapper内部的WrapperValve创建FilterChain实例,调用指定的Servlet实例处理请求。
返回
可以从以上流程中看到这个是一个标准的责任链模式,请求经过一个组件过滤后到下一个组件,每个组件只处理自己相关的事务。
事件机制
ApplicationContext 通过 ApplicationEvent 类和 ApplicationListener 接口进行事件处理。 如果将实现 ApplicationListener 接口的 bean 注入到上下文中,则每次使用 ApplicationContext 发布 ApplicationEvent 时,都会通知该 bean。本质上,这是标准的观察者设计模式。我们可以多个listener监听同一个事件,比如完成任务,会增加积分,发送消息等等,各个业务独自解耦
1 | https://blog.csdn.net/u013128651/article/details/103738170?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242 |
XML两种解析方法
DOM:Document Object Model。需要读取整个XML文档,先需要在内存中构架代表整个DOM树的Document对象,可以进行随机访问. 需要考虑内存.适合增删改
SAX:Simple API for XML。采用事件驱动的方式解析XML文件,边读边对文档进行处理.适合读取
JPA
1 | /** |
JPA - Java Persistence API,是从JDK5开始提供的,用来描述对象 <–> 关系表映射关系,并持久化的标准。也就是说,在java中,他只是一套标准接口,没了具体实现,她什么也实现不了。常见的实现有hibernate,spring data jpa。
Mybatis - 另一个思路的持久化层框架,与上述的JPA思路不同,他不是依靠ORM描述映射关系来与数据库交互的。具体可以看看MyBatis vs ORM
1 | 第一种:根据方法命名规则自动生成 findBy |
都隐藏在通过JdkDynamicAopProxy生成的动态代理对象当中
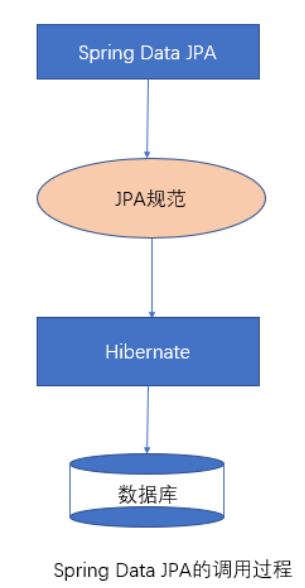
JPA对于单表的或者简单的SQL查询非常友好,甚至可以说非常智能。他为你准备好了大量的拿来即用的持久层操作方法。甚至只要写findByName这样一个接口方法,他就能智能的帮你执行根据名称查找实体类对应的表数据,完全不用写SQL。
但是,JPA对于多表关联查询以及动态SQL、自定义SQL等非常不友好。对于JPA来说,一种实现实现方式是QueryDSL,实现的代码是下面这样的。我想问:你希望用这样的代码代替SQL么?
Mybatis的原理
动态代理调用invoke
1 | public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { |
Maven的仲裁策略
最短路径优先原则
按照依赖路径的长度,长度最小的优先。
A->B->E 2.0
D ->E 1.0
同时依赖AD,则E的版本是1.0
第一声明优先原则
使用前提是:路径长度一样
A->B->E 2.0
D->C ->E 1.0
同时依赖AD,则E的版本是取决于AD的声明顺序
先声明的
为什么使用maven
项目中需要的jar包必须手动”复制”,“粘贴”到WEB-INF/lib目录下
带来的问题:同样的jar包文件重复出现在不同的项目工程中,一方面浪费存储空间,另一方面也让工程显得臃肿;
借助Maven,可以将jar包仅仅保存在”仓库中”,有需要使用的工程”引用”这个文件接口,并不需要真的吧jar包复制过来。