[TOC]
TOP指令
图一(ubuntu):
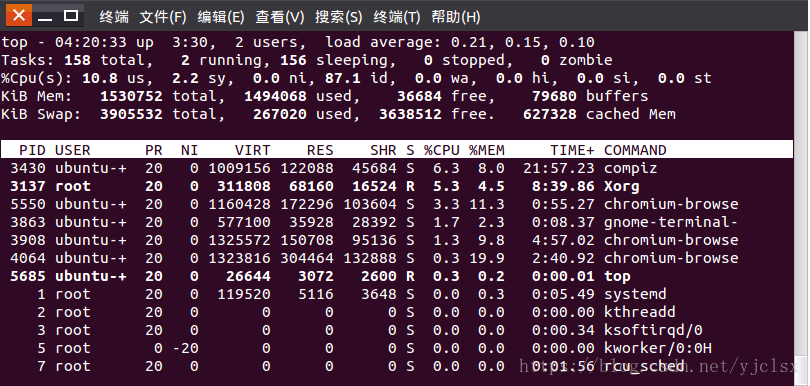
第1行:top - 05:43:27 up 4:52, 2 users, load average: 0.58, 0.41, 0.30
第1行是任务队列信息,其参数如下:
| 内容 | 含义 |
|---|---|
| 05:43:27 | 表示当前时间 |
| up 4:52 | 系统运行时间 格式为时:分 |
| 2 users | 当前登录用户数 |
| load average: 0.58, 0.41, 0.30 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
load average:
1 | 系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。 |
第2行:Tasks: 159 total, 1 running, 158 sleeping, 0 stopped, 0 zombie
第3行:%Cpu(s): 37.0 us, 3.7 sy, 0.0 ni, 59.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
第2、3行为进程和CPU的信息
当有多个CPU时,这些内容可能会超过两行,其参数如下:
| 内容 | 含义 |
|---|---|
| 159 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 158 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| 37.0 us9.3 id(考到了) | 用户空间占用CPU百分比 |
| 3.7 sy9.3 id(考到了) | 内核空间占用CPU百分比 |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 59.3 id(考到了) | 空闲CPU百分比 |
| 0.0 wa | 等待输入输出的CPU时间百分比 |
| 0.0 hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| 0.0 si | 软中断(Software Interrupts)占用CPU的百分比 |
| 0.0 st |
第4行:KiB Mem: 1530752 total, 1481968 used, 48784 free, 70988 buffers
第5行:KiB Swap: 3905532 total, 267544 used, 3637988 free. 617312 cached Mem
第4、5行为内存信息
其参数如下:
| 内容 | 含义 |
|---|---|
| KiB Mem: 1530752 total | 物理内存总量 |
| 1481968 used | 使用的物理内存总量 |
| 48784 free | 空闲内存总量 |
| 70988 buffers(buff/cache) | 用作内核缓存的内存量 |
| KiB Swap: 3905532 total | 交换区总量 |
| 267544 used | 使用的交换区总量 |
| 3637988 free | 空闲交换区总量 |
| 617312 cached Mem | 缓冲的交换区总量。 |
| 3156100 avail Mem | 代表可用于进程下一次分配的物理内存数量 |
上述最后提到的缓冲的交换区总量,这里解释一下,所谓缓冲的交换区总量,即内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
计算可用内存数有一个近似的公式:
第四行的free + 第四行的buffers + 第五行的cached
进程信息
| 列名 | 含义 |
|---|---|
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 进程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEM | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志 |
服务器IO延时高
https://www.cnblogs.com/yinzhengjie/p/9934260.html
1 | [root@kafka118 ~]# iotop -botq -p 8382 |
iotop+p
Linux系统出现了性能问题,一般我们可以通过top、iostat、iotop、free、vmstat等命令来查看初步定位问题。
今天我们讲解就是iostat和iotop,定位问题的一般步骤:
Step-1】 iostat这个命令可以给我们提供丰富的IO状态数据,一般我们先通过该命令来查看是否存在性能瓶颈
Step-2】用iotop找出io高的进程
1、iostat常见用法:
iostat -d -k 1 10 #查看TPS和吞吐量信息
参数 -d 表示,显示设备(磁盘)使用状态;
-k某些使用block为单位的列强制使用Kilobytes为单位;
1 10表示,数据显示每隔1秒刷新一次,共显示10次
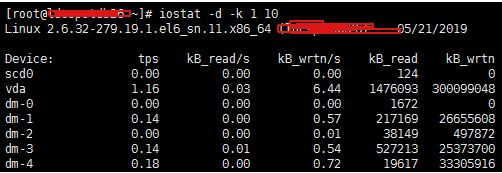
iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)
使用-x参数我们可以获得更多统计信息。
注意】一般%util大于70%,I/O压力就比较大,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。磁盘可能存在瓶颈。

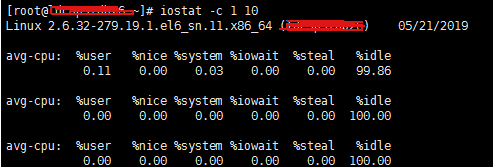
iostat还可以用来获取cpu部分状态值:
iostat -c 1 10 #查看cpu状态
注意】idle小于70% IO压力就较大了,一般读取速度有较多的wait。
2、我们通过上面iostat的常用命令基本可以判断IO是否存在瓶颈了,然后我们通过iotop命令来抓出罪魁祸首的进程,这里比较简单直接输入命令,然后执行(一般抓到的是java进程、mysqld,干的越多问题越多) 

只显示正在产生I/O的进程或线程。除了传参,可以在运行过程中按o生效。
1 | [root@node105 ~]# iotop -o |
CPU延时高
在最近上线过程中遇到cpu占用率过高问题

由于问题已解决,此时仅重现操作方法
1.先用top命令,找到cpu占用最高的进程 PID 如上图
- top –p pid
(再用ps -mp pid -o THREAD,tid,time 查询进程中,那个线程的cpu占用率高 记住TID)

3.jstack 29099 >> xxx.log 打印出该进程下线程日志

4.sz xxx.log 将日志文件下载到本地

5.将查找到的 线程占用最高的 tid 上上上图中 29108 转成16进制 — 71b4


6.打开下载好的 xxx.log 通过 查找方式 找到 对应线程 进行排查

1 | printf '%x' 32826 获取16进制的线程id,用于dump信息查询,结果为 803a。最后我们执行jstack 32805 |grep -A 20 803a |
netstat
-a 显示所有socket,包括正在监听的。
-c 每隔1秒就重新显示一遍,直到用户中断它。
-i 显示所有网络接口的信息,格式“netstat -i”。
-n 以网络IP地址代替名称,显示出网络连接情形。
-r显示核心路由表,格式同“route -e”。
-t 显示TCP协议的连接情况
-u 显示UDP协议的连接情况。
-v 显示正在进行的工作。
-p 显示建立相关连接的程序名和PID。
-b 显示在创建每个连接或侦听端口时涉及的可执行程序。
-e 显示以太网统计。此选项可以与 -s 选项结合使用。
-f 显示外部地址的完全限定域名(FQDN)。
-o显示与与网络计时器相关的信息。
-s 显示每个协议的统计。
-x 显示 NetworkDirect 连接、侦听器和共享端点。
-y 显示所有连接的 TCP 连接模板。无法与其他选项结合使用。
查看当前所有tcp端口使用情况:
netstat -a # 列出所有端口
netstat -at # 列出所有TCP端口
netstat -au # 列出所有UDP端口
netstat -ax # 列出所有unix端口
netstat -atnlp # 直接使用ip地址列出所有处理监听状态的TCP端口,且加上程序名
Proto:协议名(tcp协议还是udp协议);
recv-Q:网络接收队列
表示收到的数据已经在本地接收缓冲,但是还有多少没有被进程取走,recv()如果接收队列Recv-Q一直处于阻塞状态,可能是遭受了拒绝服务 denial-of-service 攻击;
send-Q:网路发送队列
对方没有收到的数据或者说没有Ack的,还是本地缓冲区.
如果发送队列Send-Q不能很快的清零,可能是有应用向外发送数据包过快,或者是对方接收数据包不够快;
这两个值通常应该为0,如果不为0可能是有问题的。packets在两个队列里都不应该有堆积状态。可接受短暂的非0情况。
Local Address 解释
1)Local Address 部分的0.0.0.0:873表示监听服务器上所有ip地址的所有(0.0.0.0表示本地所有ip),比如你的服务器是有172.172.230.210
Foreign Address解释
与本机端口通信的外部socket。显示规则与Local Address相同
netstat
1 | [root@xiesshavip002 ~]# netstat -a # 列出所有端口 |

1 | [root@localhost ~]# netstat -an | grep 3306 //查看所有3306端口使用情况· |
CPU暴增
如果服务器在运行中cpu突然暴增怎么排查
首先通过ps命令查看一下占用cpu最多的进程,再根据请求选择是否要杀死它还是用其他的解决方案。
然后通过stack工具打印Java的方法栈,查看是否有死锁的存在。
然后通过其他排查工具定位问题所在。如果是数据库连接的的问题,就用回滚策略解决。如果只是单纯的请求量暴增导致的,那么就先重启服务,并在以后的开发中多进行压测。
iftop
在类Unix系统中可以使用top查看系统资源、进程、内存占用等信息。查看网络状态可以使用netstat、nmap等工具。若要查看实时的网络流量,监控TCP/IP连接等,则可以使用iftop。
iftop类似于top的实时流量监控工具,可以用来监控网卡的实时流量(可以指定网段)、反向解析IP、显示端口信息等。
查看流量是从哪些端口发送出去的:
# iftop -P

-P 选项会在iftop 的输出结果中开启端口显示
界面上面显示的是类似刻度尺的刻度范围,为显示流量图形的长条作标尺用的。
中间的<= =>这两个左右箭头,表示的是流量的方向。
TX:发送流量
RX:接收流量
TOTAL:总流量
Cumm:运行iftop到目前时间的总流量
peak:流量峰值
rates:分别表示过去 2s 10s 40s 的平均流量
要找到运行在该端口的进程,那么可以用netstat 或者lsof 来找到相应的进程。
使用netstat 命令来找到运行在10910这个端口上的进程:
# netstat -tunp | grep 10910
可以使用lsof 命令来找到运行在10909这个端口上的进程:
# lsof -i:10909

查看进程PID为51919的应用程序:
# ps -ef |grep 51919

查看端口是否占用
netstat
①.\查看所有的端口占用情况****
C:>netstat -ano
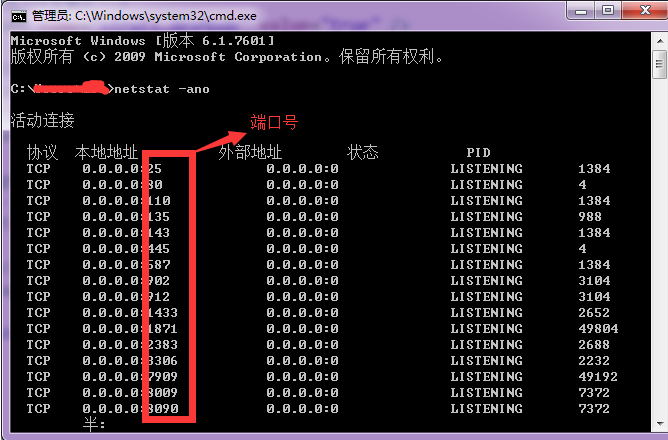
查看端口号 netstat
如果发现某个端口被占用后,可以用命令查看,该端口到底是被哪个进程所占用。命令如下:
1 | netstat -pan | grep 5623 |
如图:
发现5623的端口,被28425的进程id所占用,继续进一步跟踪,到底是哪个程序所占用了。
通过进程id查找程序–ps
直接通过:ps -aux | grep pid 查看,进程程序名称,
通过netstat查找端口占用的pid,再通过pid进一步的查找程序名称,能够确认目前冲突的端口是哪个程序已经占用了,我们是重新启用换一个端口号,还是结束已经占用的端口号所用的程序,清空被占用的端口号。
netstat 中参数选项
1 | -a或--all:显示所有连线中的Socket; |
使用命令 jstack $pid | grep “线程id” –A 30,把信息打印出来【这里的-A 30指的是30行】【线程id:根据第5步得到的1a68在pid线程信息里面去找对应线程内容】,也可以写到文件中,下载下来,通过16进制的线程id来搜索定位代码段。
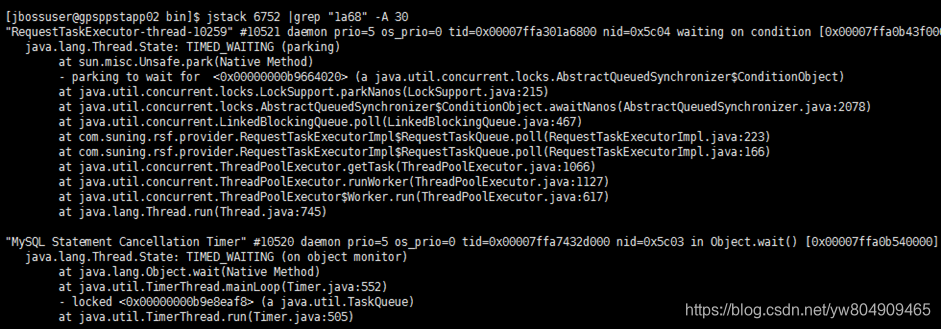
9.通过jstack命令来查看下当前内存状态,解读线程信息,定位具体代码位置,接下来就是找开发人员确认问题,看这段代码是否可以优化。
实际案例
案例一:
定位到cpu过高是IO读写太高 ,接下来就是找开发人员确认这段代码是否可以优化
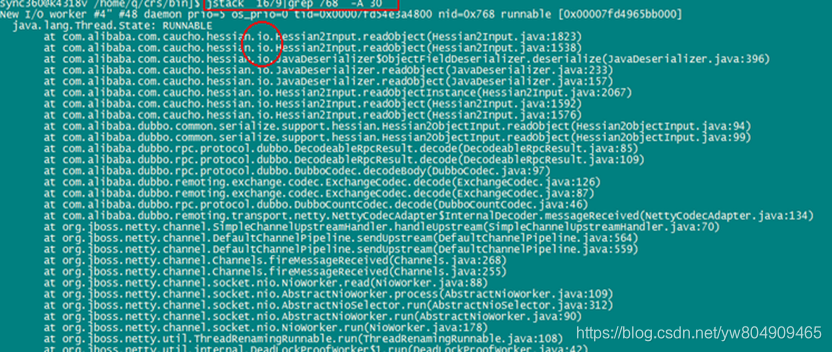
案例二:
两个线程执行过程中,需要对两个对象进行加锁,且加锁的顺序不一致,导致了死锁的产生,简单的修复方法是:对两个对象的加锁顺序一致。
注意:必须有两个可以被加锁的对象才能产生死锁,只有一个不会产生死锁问题

案例三:

案例四:
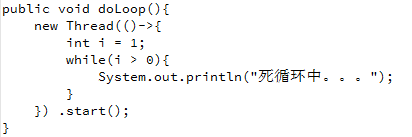
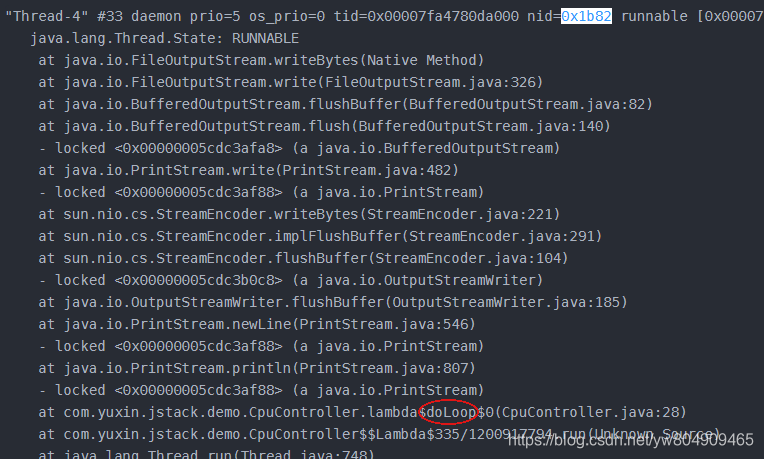
案例五:
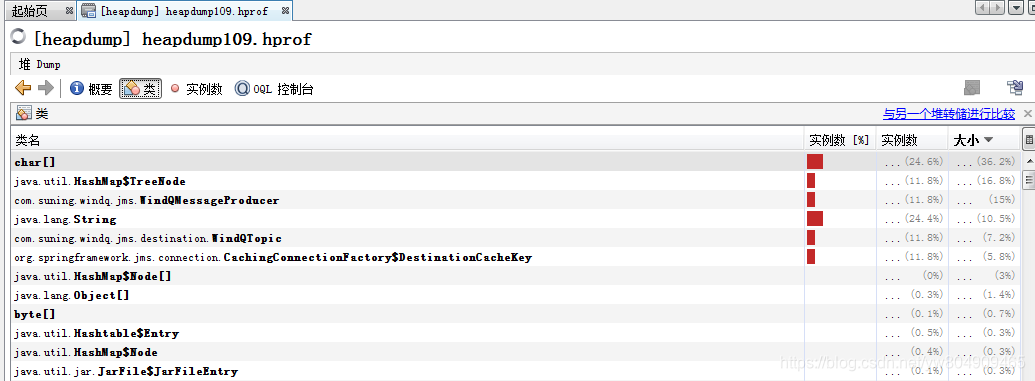
1.生产环境heap堆内存不断上升导致oom,pst环境复现heap堆内存不断上升。经过分析堆内存创建的windq主题或队列WindqQueue、WindqTopic方式会缓存到连接工厂,缓存的对象并不是根据唯一的key去缓存,而是直接使用对象的引用作缓存,导致jvm无法回收这部分内存(比如新建同一个sendOperationTopic的主题Object1,Object2,Object1和Object2都会缓存到连接工厂)。
2.pst环境百万数据重试发现栈内存溢出,由于递归调用导致,已将递归方法修改为循环的方式去调用。
结果:修改后pst环境内存回收稳定,无连接工厂大对象,堆内存,无栈内存溢出,cpu使用情况稳定。
发现程序异常前通过执行指令,直接生成当前JVM的dump文件,15434是指JVM的进程号
jmap -dump:format=b,file=serviceDump.dat 15434
查看Java进程
ps aux|grep java
netstat -ano| grep pid
tcpdump是干啥的?什么场景用?
https://www.cnblogs.com/chenpingzhao/p/9108570.html
(1).默认启动
1 | tcpdump |
默认情况下,直接启动tcpdump将监视第一个网络接口(非lo口)上所有流通的数据包。这样抓取的结果会非常多,滚动非常快。
(2).监视指定网络接口的数据包
1 | tcpdump -i eth1 |
如果不指定网卡,默认tcpdump只会监视第一个网络接口,如eth0。
(3).监视指定主机的数据包,例如所有进入或离开longshuai的数据包
1 | tcpdump host longshuai |
tcpdump采用命令行方式对接口的数据包进行筛选抓取,其丰富特性表现在灵活的表达式上。
监视指定网络的数据包,如本机与192.168网段通信的数据包,”-c 10”表示只抓取10个包
1 | tcpdump -c 10 net 192.168 |