[TOC]
- 双轴快排(DualPivotQuicksort),顾名思义有两个轴元素pivot1,pivot2,且pivot ≤
pivot2,将序列分成三段:x < pivot1、pivot1 ≤ x ≤ pivot2、x >pivot2,然后分别对三段进行递归。这个算法通常会比传统的快排效率更高,也因此被作为Arrays.java中给基本类型的数据排序的具体实现。
下面我们以JDK1.8中Arrays对int型数组的排序为例来介绍其中使用的双轴快排:
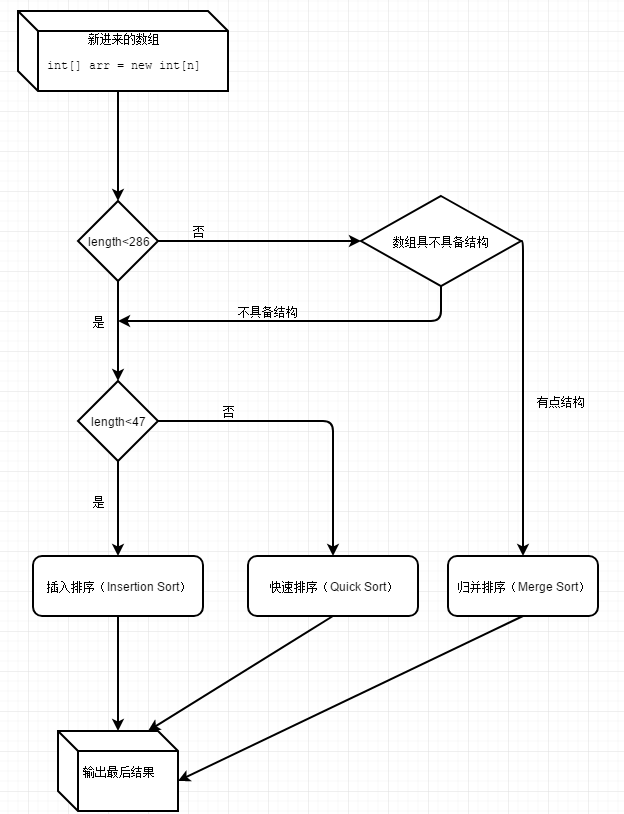
1.判断数组的长度是否大于286,大于则使用归并排序(merge sort),否则执行2。
1 | // Use Quicksort on small arrays |
2.判断数组长度是否小于47,小于则直接采用插入排序(insertion sort),否则执行3。
1 | // Use insertion sort on tiny arrays |
3.用公式length/8+length/64+1近似计算出数组长度的1/7。
1 | // Inexpensive approximation of length / 7 |
4.取5个根据经验得出的等距点。
1 | /* |
5.将这5个元素进行插入排序
1 | // Sort these elements using insertion sort |
6.选取a[e2],a[e4]分别作为pivot1,pivot2。由于步骤5进行了排序,所以必有pivot1 <=pivot2。定义两个指针less和great,less从最左边开始向右遍历,一直找到第一个不小于pivot1的元素,great从右边开始向左遍历,一直找到第一个不大于pivot2的元素。
1 | /* |
7.接着定义指针k从less-1开始向右遍历至
great,把小于pivot1的元素移动到less左边,大于pivot2的元素移动到great右边。这里要注意,我们已知great处的元素小于pivot2,但是它于pivot1的大小关系,还需要进行判断,如果比pivot1还小,需要移动到到less左边,否则只需要交换到k处。
1 | /* |
8.将less-1处的元素移动到队头,great+1处的元素移动到队尾,并把pivot1和pivot2分别放到less-1和great+1处。
1 | // Swap pivots into their final positions |
9.至此,less左边的元素都小于pivot1,great右边的元素都大于pivot2,分别对两部分进行同样的递归排序。
1 | // Sort left and right parts recursively, excluding known pivots |
10.对于中间的部分,如果大于4/7的数组长度,很可能是因为重复元素的存在,所以把less向右移动到第一个不等于pivot1的地方,把great向左移动到第一个不等于pivot2的地方,然后再对less和great之间的部分进行递归排序。
1 | /* |
另外参考了其他博文,算法思路如下:
算法步骤
1.对于很小的数组(长度小于47),会使用插入排序。
2.选择两个点P1,P2作为轴心,比如我们可以使用第一个元素和最后一个元素。
3.P1必须比P2要小,否则将这两个元素交换,现在将整个数组分为四部分:
(1)第一部分:比P1小的元素。
(2)第二部分:比P1大但是比P2小的元素。
(3)第三部分:比P2大的元素。
(4)第四部分:尚未比较的部分。
在开始比较前,除了轴点,其余元素几乎都在第四部分,直到比较完之后第四部分没有元素。
4.从第四部分选出一个元素a[K],与两个轴心比较,然后放到第一二三部分中的一个。
5.移动L,K,G指向。
6.重复 4 5 步,直到第四部分没有元素。
7.将P1与第一部分的最后一个元素交换。将P2与第三部分的第一个元素交换。
8.递归的将第一二三部分排序。
总结:Arrays.sort对升序数组、降序数组和重复数组的排序效率有了很大的提升,这里面有几个重大的优化。
1.对于小数组来说,插入排序效率更高,每次递归到小于47的大小时,用插入排序代替快排,明显提升了性能。
2.双轴快排使用两个pivot,每轮把数组分成3段,在没有明显增加比较次数的情况下巧妙地减少了递归次数。
3.pivot的选择上增加了随机性,却没有带来随机数的开销。
4.对重复数据进行了优化处理,避免了不必要交换和递归。
O(nlogn)只代表增长量级,同一个量级前面的常数也可以不一样,不同数量下面的实际运算时间也可以不一样。
数量非常小的情况下(就像上面说到的,少于47的),插入排序等可能会比快速排序更快。 所以数组少于47的会进入插入排序。
快排数据越无序越快(加入随机化后基本不会退化),平均常数最小,不需要额外空间,不稳定排序。
归排速度稳定,常数比快排略大,需要额外空间,稳定排序。
所以大于或等于47或少于286会进入快排,而在大于或等于286后,会有个小动作:“// Check if the array is nearly sorted”。这里第一个作用是先梳理一下数据方便后续的归并排序,第二个作用就是即便大于286,但在降序组太多的时候(被判断为没有结构的数据,The array is not highly structured,use Quicksort instead of merge sort.),要转回快速排序。