流程
Flink分布式快照流程
首先我们来看一下一个简单的Checkpoint的大致流程:
- 暂停处理新流入数据,将新数据缓存起来。
- 将算子子任务的本地状态数据拷贝到一个远程的持久化存储上。
- 继续处理新流入的数据,包括刚才缓存起来的数据。
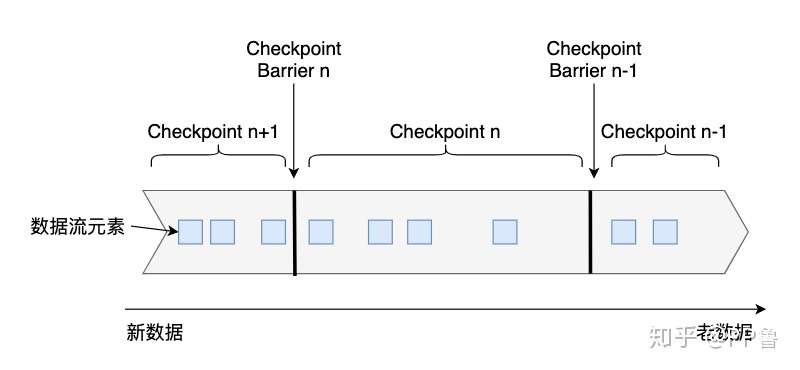
Flink是在Chandy–Lamport算法[1]的基础上实现的一种分布式快照算法。在介绍Flink的快照详细流程前,我们先要了解一下检查点分界线(Checkpoint Barrier)的概念。如下图所示,Checkpoint Barrier被插入到数据流中,它将数据流切分成段。Flink的Checkpoint逻辑是,一段新数据流入导致状态发生了变化,Flink的算子接收到Checpoint Barrier后,对状态进行快照。每个Checkpoint Barrier有一个ID,表示该段数据属于哪次Checkpoint。如图所示,当ID为n的Checkpoint Barrier到达每个算子后,表示要对n-1和n之间状态的更新做快照。Checkpoint Barrier有点像Event Time中的Watermark,它被插入到数据流中,但并不影响数据流原有的处理顺序。
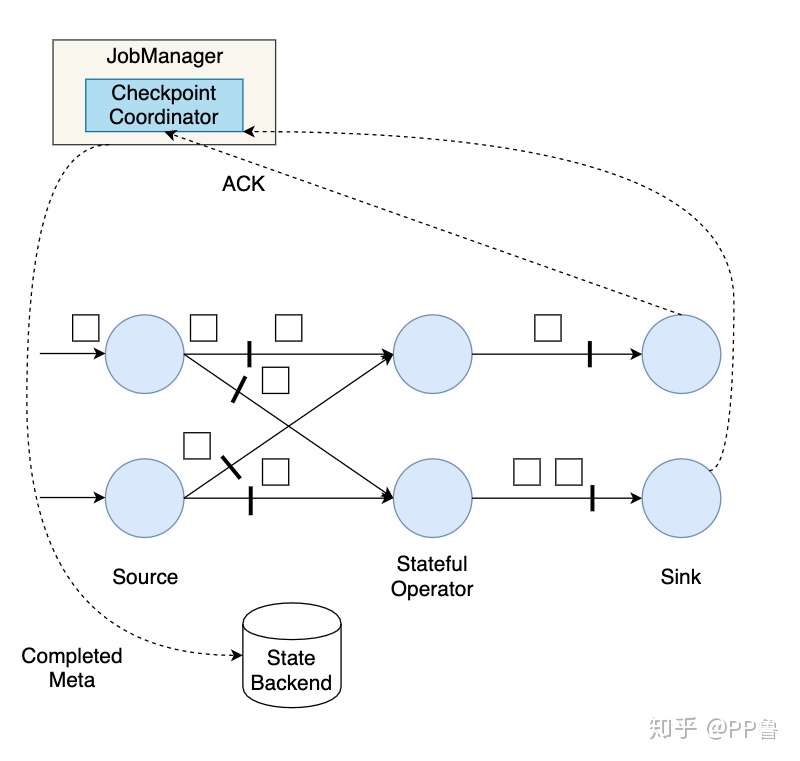
接下来,我们构建一个并行数据流图,用这个并行数据流图来演示Flink的分布式快照机制。这个数据流图有两个Source子任务,数据流会在这些并行算子上从Source流动到Sink。
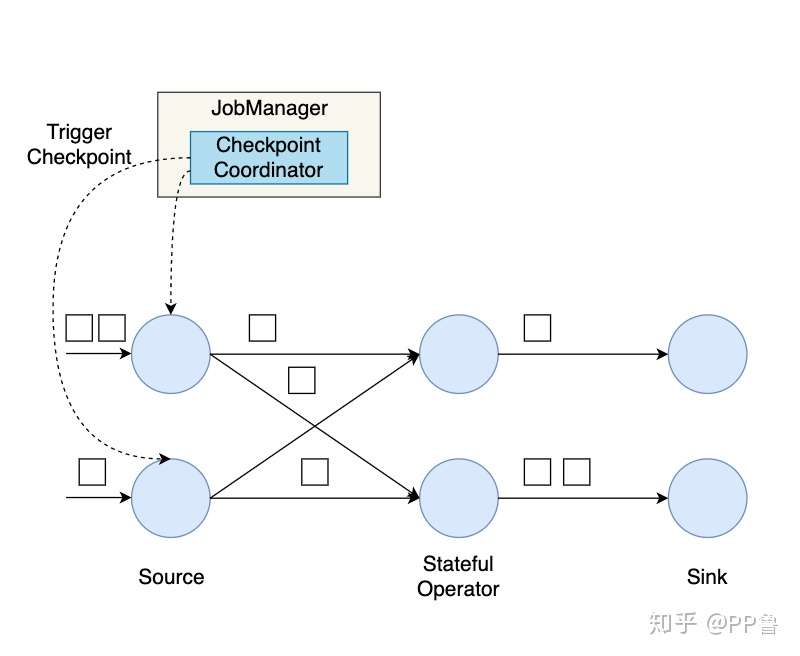
首先,Flink的检查点协调器(Checkpoint Coordinator)触发一次Checkpoint(Trigger Checkpoint),这个请求会发送给Source的各个子任务。
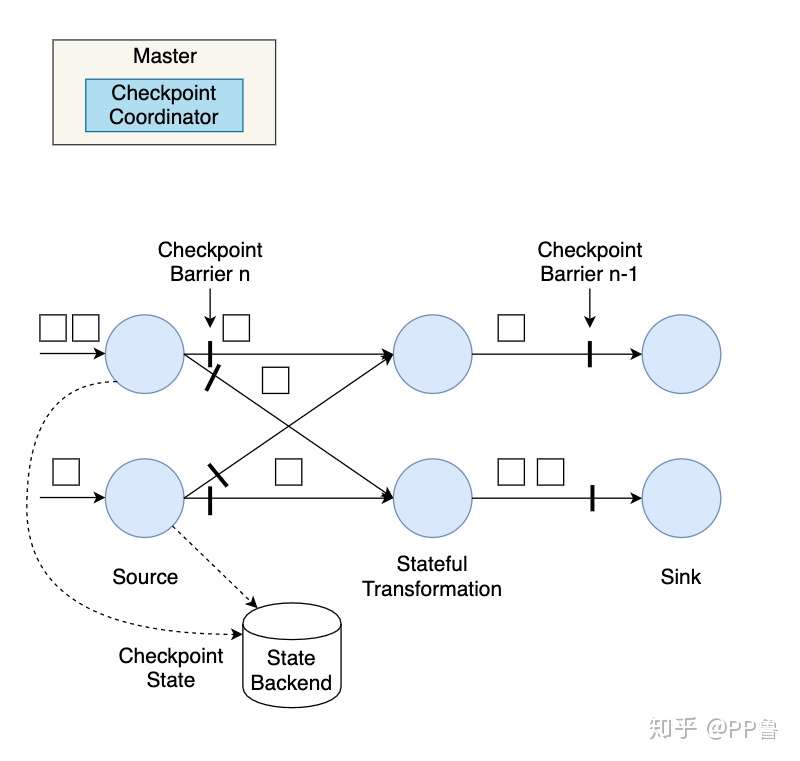
各Source算子子任务接收到这个Checkpoint请求之后,会将自己的状态写入到状态后端,生成一次快照,并且会向下游广播Checkpoint Barrier。
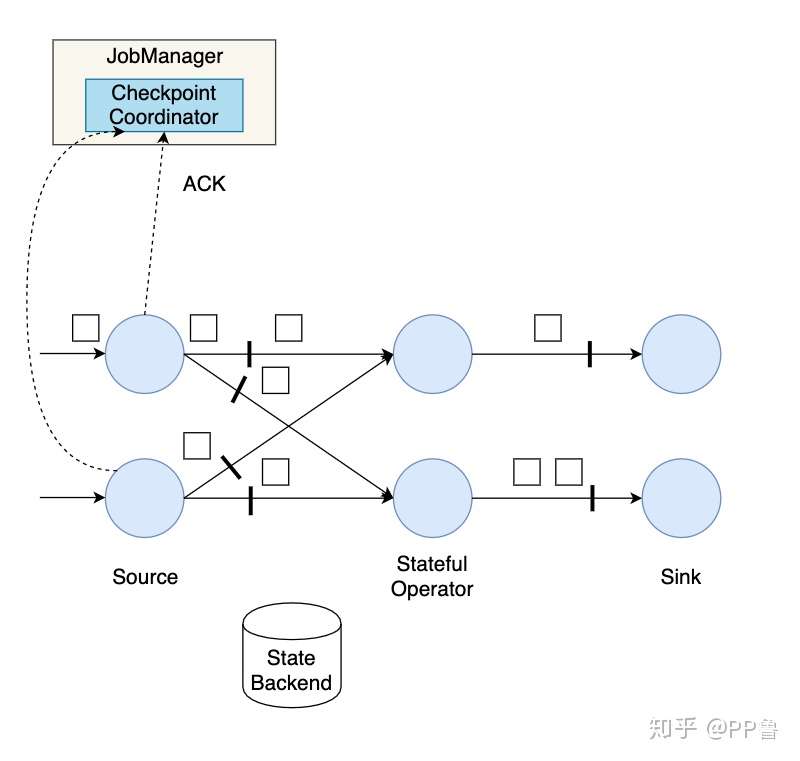
Source算子做完快照后,还会给Checkpoint Coodinator发送一个确认,告知自己已经做完了相应的工作。这个确认中包括了一些元数据,其中就包括刚才备份到State Backend的状态句柄,或者说是指向状态的指针。至此,Source完成了一次Checkpoint。跟Watermark的传播一样,一个算子子任务要把Checkpoint Barrier发送给所连接的所有下游算子子任务。
对于下游算子来说,可能有多个与之相连的上游输入,我们将算子之间的边称为通道。Source要将一个ID为n的Checkpoint Barrier向所有下游算子广播,这也意味着下游算子的多个输入里都有同一个Checkpoint Barrier,而且不同输入里Checkpoint Barrier的流入进度可能不同。Checkpoint Barrier传播的过程需要进行对齐(Barrier Alignment),我们从数据流图中截取一小部分来分析Checkpoint Barrier是如何在算子间传播和对齐的。
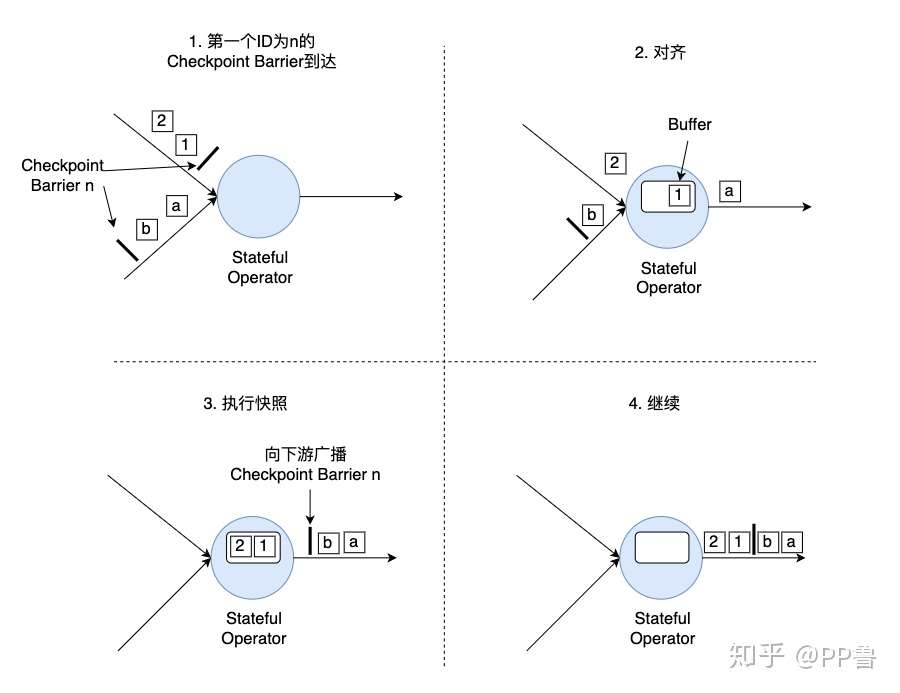
如上图所示,对齐分为四步:
- 算子子任务在某个输入通道中收到第一个ID为n的Checkpoint Barrier,但是其他输入通道中ID为n的Checkpoint Barrier还未到达,该算子子任务开始准备进行对齐。
- 算子子任务将第一个输入通道的数据缓存下来,同时继续处理其他输入通道的数据,这个过程被称为对齐。
- 第二个输入通道的Checkpoint Barrier抵达该算子子任务,该算子子任务执行快照,将状态写入State Backend,然后将ID为n的Checkpoint Barrier向下游所有输出通道广播。
- 对于这个算子子任务,快照执行结束,继续处理各个通道中新流入数据,包括刚才缓存起来的数据。
数据流图中的每个算子子任务都要完成一遍上述的对齐、快照、确认的工作,当最后所有Sink算子确认完成快照之后,说明ID为n的Checkpoint执行结束,Checkpoint Coordinator向State Backend写入一些本次Checkpoint的元数据。
之所以要进行对齐,主要是为了保证一个Flink作业所有算子的状态是一致的。也就是说,某个ID为n的Checkpoint Barrier从前到后流入所有算子子任务后,所有算子子任务都能将同样的一段数据写入快照。
快照性能优化方案
前面和大家分享了一致性快照的具体流程,这种方式保证了数据的一致性,但有一些潜在的问题:
- 每次进行Checkpoint前,都需要暂停处理新流入数据,然后开始执行快照,假如状态比较大,一次快照可能长达几秒甚至几分钟。
- Checkpoint Barrier对齐时,必须等待所有上游通道都处理完,假如某个上游通道处理很慢,这可能造成整个数据流堵塞。
针对这些问题Flink已经有了一些解决方案,并且还在不断优化。
对于第一个问题,Flink提供了异步快照(Asynchronous Snapshot)的机制。当实际执行快照时,Flink可以立即向下广播Checkpoint Barrier,表示自己已经执行完自己部分的快照。同时,Flink启动一个后台线程,它创建本地状态的一份拷贝,这个线程用来将本地状态的拷贝同步到State Backend上,一旦数据同步完成,再给Checkpoint Coordinator发送确认信息。拷贝一份数据肯定占用更多内存,这时可以利用写入时复制(Copy-on-Write)的优化策略。Copy-on-Write指:如果这份内存数据没有任何修改,那没必要生成一份拷贝,只需要有一个指向这份数据的指针,通过指针将本地数据同步到State Backend上;如果这份内存数据有一些更新,那再去申请额外的内存空间并维护两份数据,一份是快照时的数据,一份是更新后的数据。
对于第二个问题,Flink允许跳过对齐这一步,或者说一个算子子任务不需要等待所有上游通道的Checkpoint Barrier,直接将Checkpoint Barrier广播,执行快照并继续处理后续流入数据。为了保证数据一致性,Flink必须将那些较慢的数据流中的元素也一起快照,一旦重启,这些元素会被重新处理一遍。
State Backend
前面已经分享了Flink的快照机制,其中State Backend起到了持久化存储数据的重要功能。Flink将State Backend抽象成了一种插件,并提供了三种State Backend,每种State Backend对数据的保存和恢复方式略有不同。接下来我们开始详细了解一下Flink的State Backend。
MemoryStateBackend
从名字中可以看出,这种State Backend主要基于内存,它将数据存储在Java的堆区。当进行分布式快照时,所有算子子任务将自己内存上的状态同步到JobManager的堆上,一个作业的所有状态要小于JobManager的内存大小。这种方式显然不能存储过大的状态数据,否则将抛出OutOfMemoryError异常。因此,这种方式只适合调试或者实验,不建议在生产环境下使用。下面的代码告知一个Flink作业使用内存作为State Backend,并在参数中指定了状态的最大值,默认情况下,这个最大值是5MB。
1 | env.setStateBackend(new MemoryStateBackend(MAX_MEM_STATE_SIZE)) |
如果不做任何配置,默认情况是使用内存作为State Backend。
FsStateBackend
这种方式下,数据持久化到文件系统上,文件系统包括本地磁盘、HDFS以及包括Amazon、阿里云在内的云存储服务。使用时,我们要提供文件系统的地址,尤其要写明前缀,比如:file://、hdfs://或s3://。此外,这种方式支持Asynchronous Snapshot,默认情况下这个功能是开启的,可加快数据同步速度。
1 | // 使用HDFS作为State Backend |
Flink的本地状态仍然在TaskManager的内存堆区上,直到执行快照时状态数据会写到所配置的文件系统上。因此,这种方式能够享受本地内存的快速读写访问,也能保证大容量状态作业的故障恢复能力。
RocksDBStateBackend
这种方式下,本地状态存储在本地的RocksDB上。RocksDB是一种嵌入式Key-Value数据库,数据实际保存在本地磁盘上。比起FsStateBackend的本地状态存储在内存中,RocksDB利用了磁盘空间,所以可存储的本地状态更大。然而,每次从RocksDB中读写数据都需要进行序列化和反序列化,因此读写本地状态的成本更高。快照执行时,Flink将存储于本地RocksDB的状态同步到远程的存储上,因此使用这种State Backend时,也要配置分布式存储的地址。Asynchronous Snapshot在默认情况也是开启的。
此外,这种State Backend允许增量快照(Incremental Checkpoint),Incremental Checkpoint的核心思想是每次快照时只对发生变化的数据增量写到分布式存储上,而不是将所有的本地状态都拷贝过去。Incremental Checkpoint非常适合超大规模的状态,快照的耗时将明显降低,同时,它的代价是重启恢复的时间更长。默认情况下,Incremental Checkpoint没有开启,需要我们手动开启。
1 | // 开启Incremental Checkpoint |
相比FsStateBackend,RocksDBStateBackend能够支持的本地和远程状态都更大,Flink社区已经有TB级的案例。
除了上述三种之外,开发者也可以自行开发State Backend的具体实现。
重启恢复流程
Flink的重启恢复逻辑相对比较简单:
- 重启应用,在集群上重新部署数据流图。
- 从持久化存储上读取最近一次的Checkpoint数据,加载到各算子子任务上。
- 继续处理新流入的数据。
这样的机制可以保证Flink内部状态的Excatly-Once一致性。至于端到端的Exactly-Once一致性,要根据Source和Sink的具体实现而定。当发生故障时,一部分数据有可能已经流入系统,但还未进行Checkpoint,Source的Checkpoint记录了输入的Offset;当重启时,Flink能把最近一次的Checkpoint恢复到内存中,并根据Offset,让Source从该位置重新发送一遍数据,以保证数据不丢不重。像Kafka等消息队列是提供重发功能的,socketTextStream就不具有这种功能,也意味着不能保证Exactly-Once投递保障。
源码分析
checkpoint是Flink Fault Tolerance机制的重要构成部分,flink checkpoint的核心类名为org.apache.flink.runtime.checkpoint.CheckpointCoordinator。
定期产生的checkpoint事件
flink的checkpoint是由CheckpointCoordinator内部的一个timer线程池定时产生的,具体代码由ScheduledTrigger这个Runnable类启动。
1 | private final class ScheduledTrigger implements Runnable { |
整个triggerCheckpoint方法大致分为三个部分:
1 环境前置检查
主要在生成一个chepoint之前进行了一些pre-checks,包括checkpoint的targetDirectory、正在进行中的pendingCheckpoint数量上限、前后两次checkpoint间隔是否过小、以及下游与checkpoint相关tasks是否存活等检测,任意一个条件不满足的都不会执行真正的checkpoint动作。
2 生成pendingcheckpoint
pendingcheckpoint表示一个待处理的检查点,每个pendingcheckpoint标有一个全局唯一的递增checkpointID,并声明了一个canceller用于后续超时情况下的checkpoint清理用于释放资源。
pendingcheckpoint在正式执行前还会再执行一遍前置检查,主要等待完成的检查点数量是否过多以及前后两次完成的检查点间隔是否过短等问题,这些检查都通过后,会把之前定义好的cancller注册到timer线程池,如果等待时间过长会主动回收checkpoint的资源。
3 启动checkpoint执行
发送这个checkpoint的checkpointID和timestamp到各个对应的executor,也就是给各个TaskManger发一个TriggerCheckpoint类型的消息。
1 | CheckpointOptions checkpointOptions; |
其中,for (Execution execution: executions) 这里面的executions里面是所有的输入节点,也就是flink source节点,所以checkpoint这些barrier 时间首先从jobmanager发送给了所有的source task
1 | JobCheckpointingSettings settings = new JobCheckpointingSettings( |
barrier源码分析
Job 启动的时候,Flink 会 startCheckpointScheduler
1 | public void startCheckpointScheduler() { |
通过定时任务来触发 checkpoint。
到 Task.triggerCheckpoint
1 | @Override |
到 Task.triggerCheckpointBarrier
1 | // trigger operator chain trigger checkpoint 最终触发 triggerCheckpointBarrier |
我们以 SourceStreamTask 为例,进入
1 | public boolean triggerCheckpoint(CheckpointMetaData checkpointMetaData, CheckpointOptions checkpointOptions) throws Exception { |
StreamTask.performCheckpoint
1 | // trigger opator chain 一路调用到这里,开始出现 barrier (实际上是定时任务 checkpoint 产生的) |